WebMagic记录
1.框架:
是一个Java的爬虫框架,底层仍然还是HttpClient 和jsoup
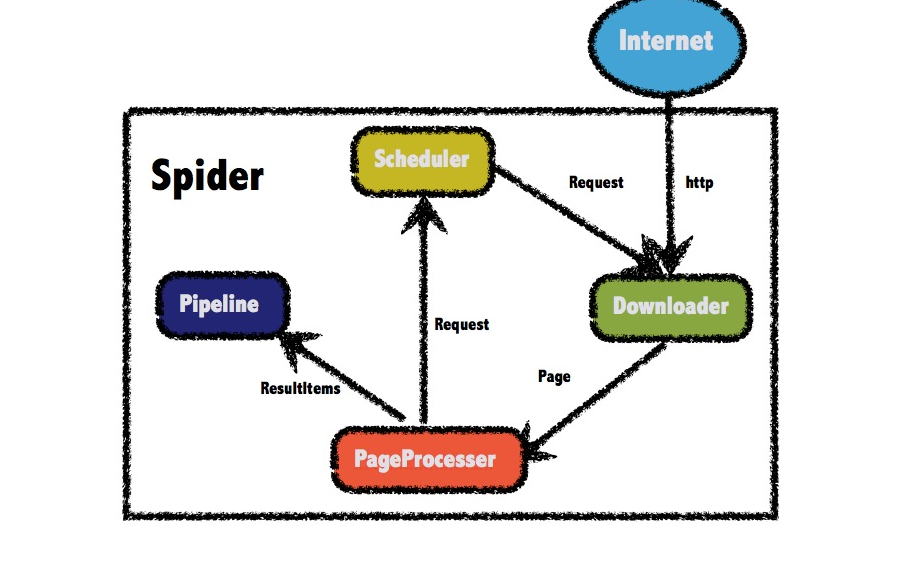
1.WebMagic的四个组件
1.Downloader(下载器组件)
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor(页面解析组件)
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,
PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler(范文队列)
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline(数据持久化)
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
组件介绍:
DownLoad:
下载器组件: 使用HttpClient来进行实现:
2、pageproccess:
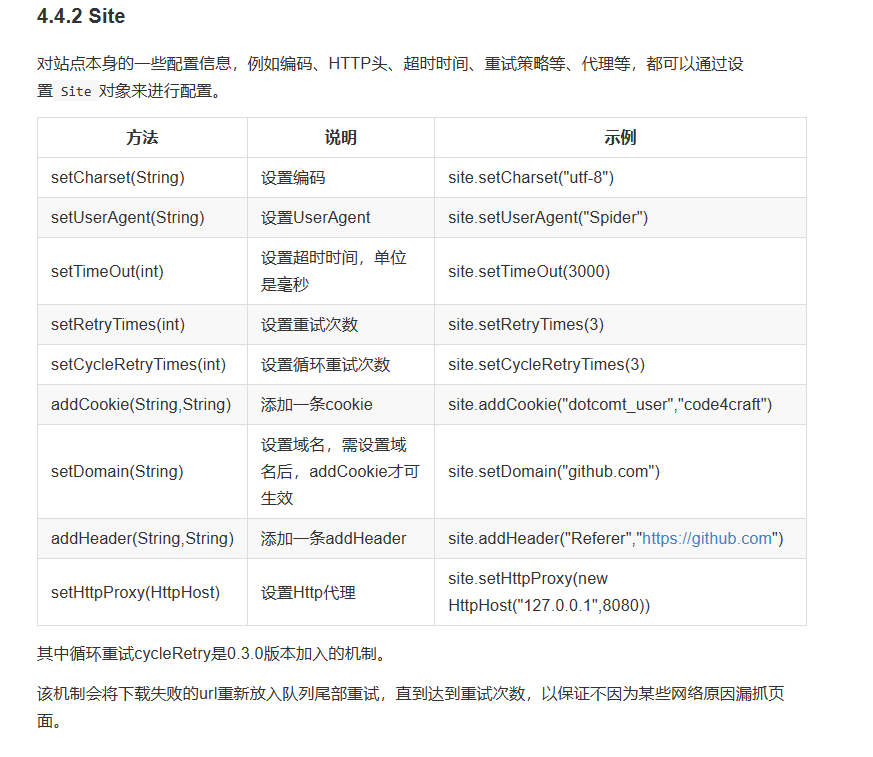
site 代表一个站点:
可以设置抓取频率:
site
如果没有特需需求,直接就是默认需求:
Page:
2
3
getResultItems(): 返回ResultItems对象,向pipeline中传递对象
>addTargetRequest() 添加请求的url
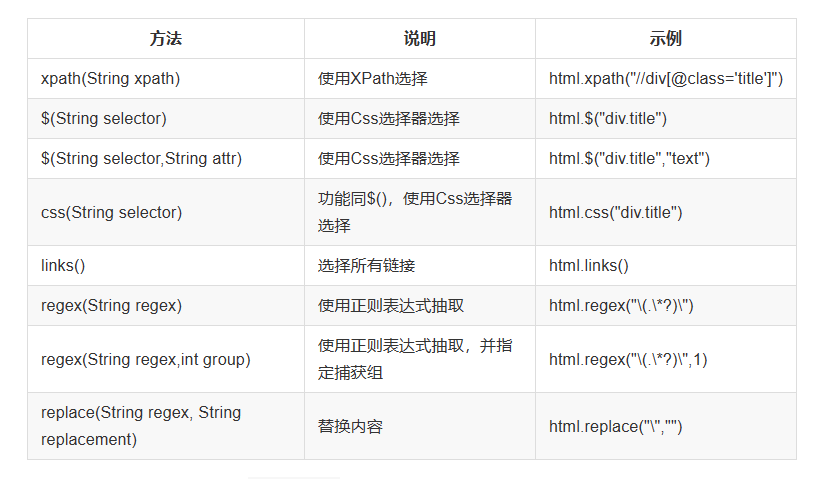
Html:
page.getHtml()返回的是一个
Html对象,它实现了Selectable接口。这个接口包含一些重要的方法,我将它分为两类:抽取部分和获取结果部分。一个Selectable就可以表示dom结点
使用html来解析
jsoup原生
使用css进行解析
使用xpath进行解析
好了,爬虫编写完成,现在我们可能还有一个问题:我如果想把抓取的结果保存下来,要怎么做呢?WebMagic用于保存结果的组件叫做
Pipeline。例如我们通过“控制台输出结果”这件事也是通过一个内置的Pipeline完成的,它叫做ConsolePipeline。那么,我现在想要把结果用Json的格式保存下来,怎么做呢?我只需要将Pipeline的实现换成”JsonFilePipeline”就可以了。
2
3
4
5
6
7
8
9
10
Spider.create(new GithubRepoPageProcessor())
//从"https://github.com/code4craft"开始抓
.addUrl("https://github.com/code4craft")
.addPipeline(new JsonFilePipeline("D:\\webmagic\\"))
//开启5个线程抓取
.thread(5)
//启动爬虫
.run();
}




