Redis: 1、redis介绍 1.1、redis是什么? Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件 。 它支持 多种类型的数据结构,如
字符串(strings) 散列(hashes) 列表(lists)
集合(sets)
有序集合 (sorted sets) 与范围查询 bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询 Redis 内置了 复制(replication ,LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions)和不同级 别的 磁盘持久化(persistence), 并通过Redis哨兵(Sentinel) 和自动分区(Cluster)提供高可用性(high availability)
1.2 性能
下面是官方的bench-mark数据: 测试完成了50个并发执行100000个请求。 设置和获取的值是一个256字节字符串。 结果:读的速度是110000次/s,写的速度是81000次/s
string 、 hash 、 list 、 set 、 sorted set
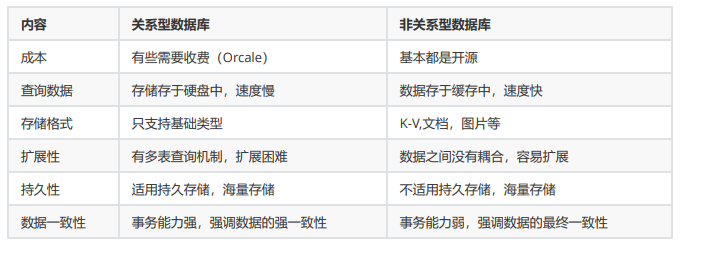
2.关系型数据库与非关系型数据库: 2.1、 关系型数据库 采用关系模型来组织数据的数据库,关系模型就是二维表格模型。一张二维表的表名就是关系,二维表中的一行就 是一条记录,二维表中的一列就是一个字段。
优点
容易理解 使用方便,
通用的sql语言 易于维护,
丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大降低了数据冗余和数据不一致的概率
缺点
磁盘I/O是并发的瓶颈
海量数据查询效率低
横向扩展困难,无法简单的通过添加硬件和服务节点来扩展性能和负载能力,当需要对数据库进行升级和扩展 时,需要停机维护和数据迁移
多表的关联查询以及复杂的数据分析类型的复杂sql查询,性能欠佳。因为要保证acid,必须按照三范式设计。(多表查询尽量不要超过四张表)
数据库:
Orcale,Sql Server,MySql,DB2
2.2、非关系型数据库
非关系型,分布式,一般不保证遵循ACID原则(原子性、 一致性 、 独立性 及 持久性 )和数据存储系统,键值对存储,结构不稳定
优点:
根据需要添加字段,不需要多表联查。仅需要id取出对应的value
适用于SNS(社会化网络服务软件。比如facebook,微博)
严格上讲不是一种数据库,而是一种数据结构化存储方法的集合
缺点 :
只适合存储一些较为简单的数据
不合适复杂查询的数据
不合适持久存储海量数据
数据库:
数据库 K-V:Redis,Memcache
文档:MongoDB
搜索:Elasticsearch,Solr
可扩展性分布式:HBase
Ubuntu apt 命令安装 在 Ubuntu 系统安装 Redis 可以使用以下命令:
1 2 # sudo apt update # sudo apt install redis-server
关闭
sudo service redis-server stop
开启服务
sudo servcie redis-server start
重启服务
sudo service redis-server restart
修改redis配置 远程访问: 1 sudo vim /etc/redis/redic.conf
注释掉本机ip
# bind 127.0.0.1 protected-mode no #将yes修改成no
重启一下服务:
sudo service redis-server restart 就可以了。
就可以远程 RedisDesktop Manager 可视化客户端连接了。
启动 Redis 查看 redis 是否启动 以上命令将打开以下终端:
127.0.0.1 是本机 IP ,6379 是 redis 服务端口。现在我们输入 PING 命令。
1 2 redis 127.0.0.1:6379> ping PONG
Redis介绍相关知识
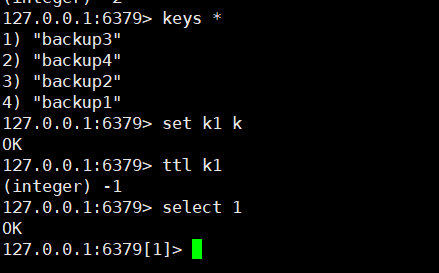
默认16个数据库,类似数组下标从0开始,初始默认使用0号库
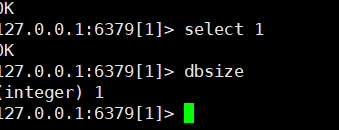
使用命令 select 来切换数据库。如: select 8
统一密码管理,所有库同样密码。
dbsize 查看当前数据库的key的数量
flushdb 清空当前库
flushall 通杀全部库
Redis是单线程+多路IO复用技术
多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)
串行 vs 多线程+锁(memcached) vs 单线程+多路IO复用(Redis)
Redis(键)
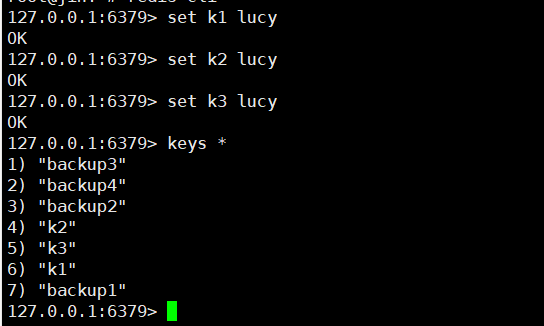
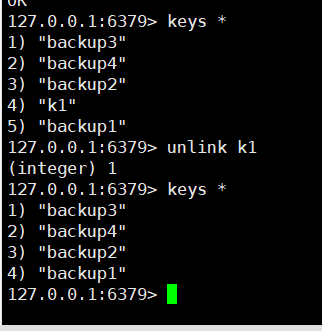
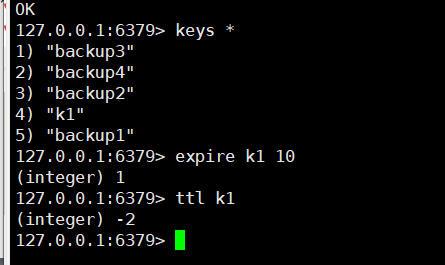
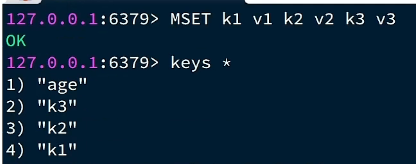
查看当前库所有key (匹配:keys *) , 不建议在生产环境中使用,因为如果数据量大,会造成阻塞
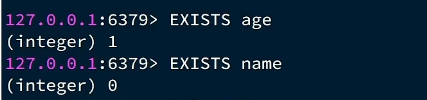
查看你的key是什么类型
删除指定的key数据
10秒钟:为给定的key设置过期时间
查看还有多少秒过期,-1表示永不过期,-2表示已过期
命令切换数据库
查看当前数据库的key的数量
清空当前库
通杀全部库
redis -cli 操作redis 五种类型
1、字符串(String)
String是Redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M
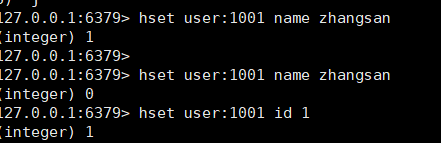
*NX:当数据库中key不存在时,可以将key-value添加数据库
*XX:当数据库中key存在时,可以将key-value添加数据库,与NX参数互斥
*EX:key的超时秒数
*PX:key的超时毫秒数,与EX互斥
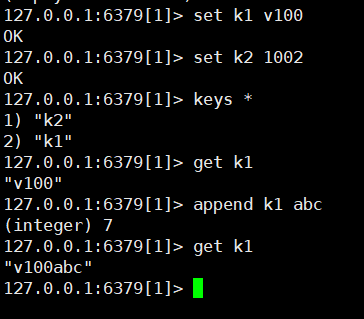
添加一条数据
获取一条数据
追加一条数据
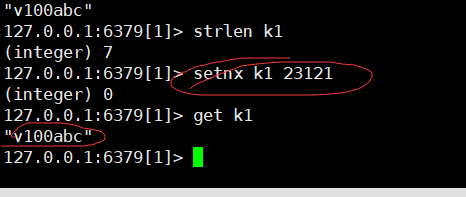
获得值的长度
只有在 key 不存在时 设置 key 的值
Mset 添加多条数据
Mget 获取多条数据
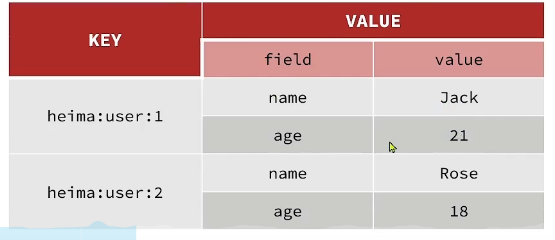
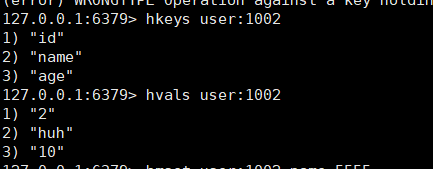
2、哈希(hash)
Hash 类型,也叫散列,其值是一个无序的字典,类似于java 中的HashMap结构
String 结构将对象序列化JSON字符串后存储,单需要修改对象某个字段时很不方便
Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做crud
同时将多个 field-value (域-值)对设置到哈希表 key 中。
HMGET key field1 field2] 获取所有给定字段的值
迭代哈希表中的键值对。
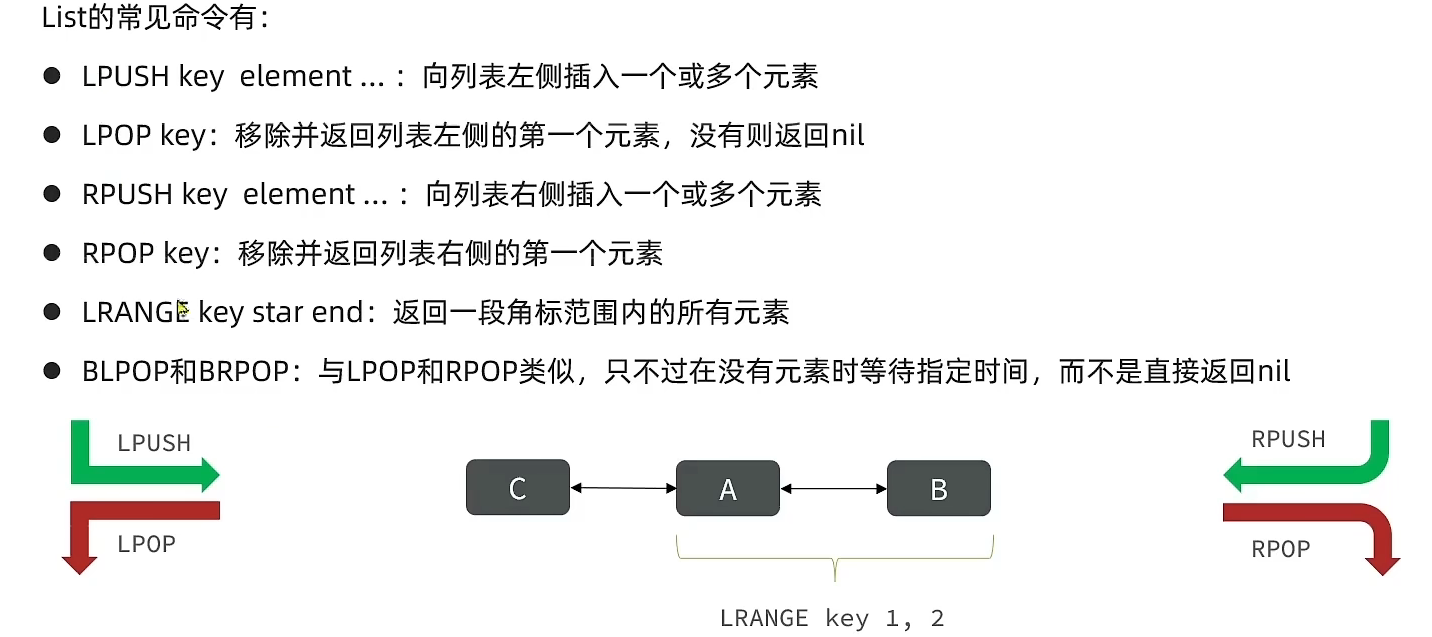
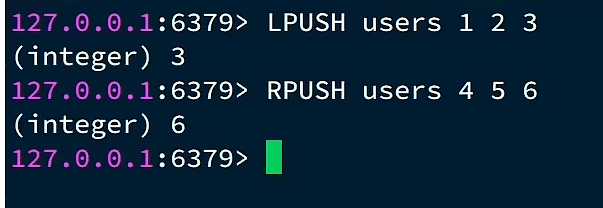
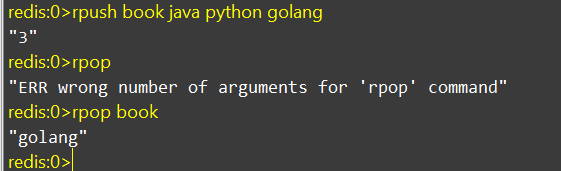
3、列表(List)
与Java 中的LinkedList,可以看作一个双向链表结构。及支持正向也支持反向检索.常用来做异步处理操作。将需要延后处理的任务结构体序列化成字符串,塞进Redis列表,另一个线程轮询读取
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
如何使用List结构模拟一个栈:
进:Lpush
出:Lpop
如何利用List结构模拟一个队列: 先进先出
如何利用List结构模拟一个阻塞队列: 入口和出口在不同的边
出队采用BLPOP或者BRPOP
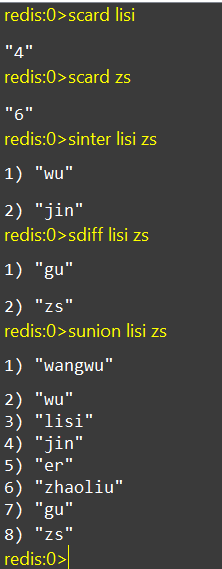
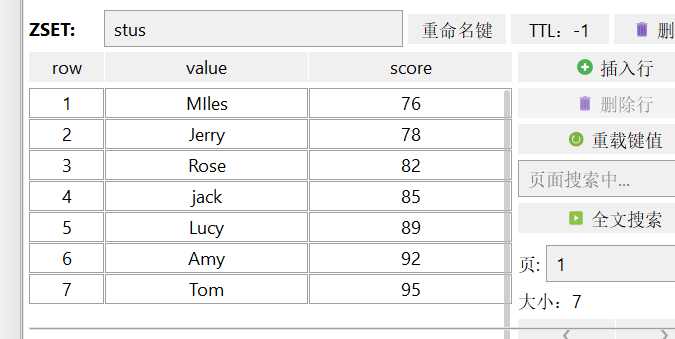
4、Redis 有序集合(Zset)
redis 的set 是String 类型的无序的集合 ,相当于java 语言,键值是无序的,唯一的 。集合中不能出现重复的数据
集合对象的编码可以是insert 或者是 hashtable。
无序、元素不可重复、查找快、支持交集、并集、差集等功能,可以保证用户不会中奖两次。
向集合添加一个或多个成员
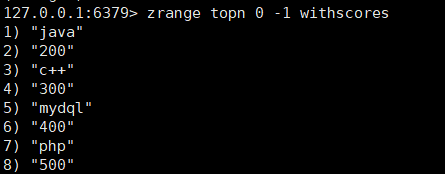
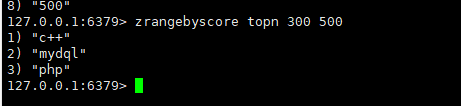
5、SortSet redis
返回成员member在集合中的排名,从0开始
返回member的分值
返回 介于两者之间的成员
获取之间的数据
Redis的Java客户端:
Jedis 以Redis命令作为方法名称。学习成本低简单实用,但是Jedis实例是线程不安全的的。多线程情况下需要进行连接池连接
Lettuce 是基于Netty实现的,支持同步、异步和响应式编程方式,
Redission是一个基于Redis实现的分布式、可伸缩的Java数据结构集合。包含诸如Map、Queue、Lock、Semaphore、AtomicLong等强大功能
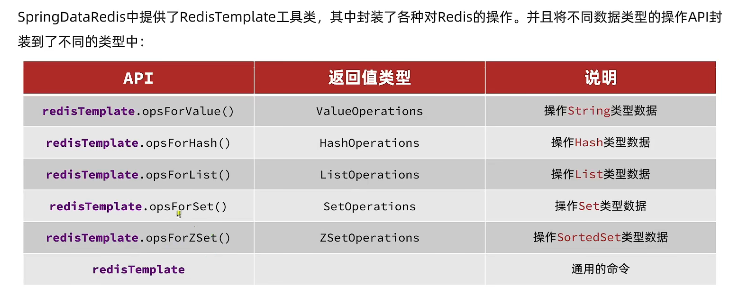
SpringDataRedis
Java使用jedis操作redis: 1、导入maven 依赖: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12 </version> <scope>test</scope> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9 .0 </version> </dependency> </dependencies>
ipv4地址:192.168.0.127
2、连接redis测试: 1 2 3 4 5 6 7 8 9 10 @Test public void initConn01 () Jedis jedis = new Jedis("192.168.0.127" ,6379 ); jedis.select(0 ); String result = jedis.ping(); System.out.println("result = " + result); System.out.println(jedis.get("username" )); }
3、通过redis连接池获取连接的对象 连接池:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 package com.wz.Jedis;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;import redis.clients.jedis.JedisPoolConfig;import java.io.*;public class JedisUtil private static final String ADDR = "192.168.0.127" ; private static final Integer PORT =6379 ; private static final String Auth ="root" ; private static final int MAX_ACTIVE = 1024 ; private static final int MAX_WAIT = 10000 ; private static final int TIMEOUT = 10000 ; private static final boolean TEST_ON_BORROW = true ; private static JedisPool jedisPool = null ; static { try { JedisPoolConfig config =new JedisPoolConfig(); config.setMaxTotal(MAX_ACTIVE); config.setMaxIdle(MAX_WAIT); config.setTestOnBorrow(TEST_ON_BORROW); jedisPool = new JedisPool(config,ADDR,PORT,TIMEOUT); }catch (Exception e){ e.printStackTrace(); } } public synchronized static Jedis getJedis () try { if (jedisPool != null ) return jedisPool.getResource(); else return null ; } catch (Exception e) { e.printStackTrace(); return null ; } } public static void returnResource (final Jedis jedis ) if (jedis != null ){ jedisPool.close(); } }
测试类: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 package com.wz;import com.wz.Jedis.JedisUtil;import com.wz.Jedis.SerializeUtil;import com.wz.entity.User;import org.junit.After;import org.junit.Before;import org.junit.Test;import org.junit.validator.PublicClassValidator;import redis.clients.jedis.Jedis;import redis.clients.jedis.Transaction;import java.sql.SQLOutput;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.Set;public class TestRedis02 Jedis jedis = null ; @Before public void init () jedis = JedisUtil.getJedis(); jedis.select(2 ); } @After public void close () JedisUtil.returnResource(jedis); } @Test public void testString () jedis.set("username" , "zhangsan" ); System.out.println(jedis.get("username" )); jedis.mset("age" , "18" , "sex" , "男" ); List<String> list = jedis.mget("username" , "age" , "sex" ); list.stream().forEach(System.out::println); Map<String,String> map = new HashMap<>(); map.put("age" ,"20" ); map.put("sex" ,"1" ); jedis.hmset("userInfo" ,map); Map<String,String> map1=jedis.hgetAll("userInfo" ); System.out.println("map1 = " + map1); } @Test public void testList () jedis.lpush("student" ,"zhangshang" ,"list1" ); List<String> student=jedis.lrange("student" ,0 ,1 ); student.stream().forEach(System.out::println); Long total = jedis.llen("student" ); System.out.println("total = " + total); System.out.println("-------------" ); jedis.lrem("student" ,0 ,"list1" ); System.out.println(jedis.llen("student" )); System.out.println("-------------" ); jedis.del("student" ); } @Test public void testSortedSet () Map<String,Double> scoreMember = new HashMap<>(); scoreMember.put("zhangsan" ,99D ); scoreMember.put("lisi" ,96D ); scoreMember.put("lisi" ,92D ); scoreMember.put("tianqi" ,95D ); jedis.zadd("score" ,scoreMember); jedis.zrange("score" ,0 ,jedis.zcard("score" )).stream().forEach(System.out::println); System.out.println("------------" ); System.out.println(jedis.zrem("score" , "zhangsan" )); jedis.zrange("score" ,0 ,jedis.zcard("score" )).stream().forEach(System.out::println); jedis.del("score" ); } @Test public void testString02 () jedis.set("user_20190304001" ,"zhangsan" ); System.out.println(jedis.get("user_20190304001" )); jedis.set("order:user_2019_wz" ,"我是订单" ); } @Test public void testKey () System.out.println(jedis.dbSize()); Set<String> set = jedis.keys("s*" ); set.stream().forEach(System.out::println); } @Test public void testTx () Transaction tx = jedis.multi(); tx.set("phoneNum" ,"10086" ); tx.discard(); } @Test public void testByte () byte [] key = SerializeUtil.serialize("userObject" ); User u = (User) SerializeUtil.unserialize(jedis.get(key)); System.out.println(u.toString()); } }
测试类对象:
4、程序序列化: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package com.wz.Jedis;import java.io.ByteArrayInputStream;import java.io.ByteArrayOutputStream;import java.io.ObjectInputStream;import java.io.ObjectOutputStream;public class SerializeUtil public static byte [] serialize(Object object){ ObjectOutputStream objectOutputStream = null ; ByteArrayOutputStream baos = null ; try { baos = new ByteArrayOutputStream(); objectOutputStream = new ObjectOutputStream(baos); objectOutputStream.writeObject(object); byte [] bytes = baos.toByteArray(); return bytes; }catch (Exception e){ e.printStackTrace(); } return null ; } public static Object unserialize (byte [] bytes) if (bytes ==null ) return null ; ByteArrayInputStream bais = null ; try { bais = new ByteArrayInputStream(bytes); ObjectInputStream objectInputStream = new ObjectInputStream(bais); return objectInputStream.readObject(); }catch (Exception e){ e.printStackTrace(); } return null ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Test public void testByte () byte [] key = SerializeUtil.serialize("userObject" ); User user = new User(); user.setUsername("wz" ); user.setPassword("1121222" ); byte [] value = SerializeUtil.serialize(user); User u = (User) SerializeUtil.unserialize(jedis.get(key)); System.out.println(u.toString()); }
SpringDataRedis: 引入依赖: 1 2 3 4 5 6 7 8 9 10 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-redis</artifactId > </dependency > <dependency > <groupId > org.apache.commons</groupId > <artifactId > commons-pool2</artifactId > </dependency >
配置yml:
1 2 3 4 5 6 7 8 9 10 11 12 redis: timeout: 10000ms host: 120.26 .160 .122 port: 6379 database: 0 lettuce: pool: max-active: 1024 max-wait: 10000ms max-idle: 200 min-idle: 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;import org.springframework.data.redis.serializer.RedisSerializer;@Configuration public class RedisConfig @Bean public RedisTemplate<String,Object> redisTemplate (LettuceConnectionFactory redisConnectionFactory) RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>(); redisTemplate.setKeySerializer(RedisSerializer.string()); redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer()); redisTemplate.setHashKeySerializer(RedisSerializer.string()); redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer()); redisTemplate.setConnectionFactory(redisConnectionFactory); return redisTemplate; } }
5、redis实现事务:
什么是悲观锁和乐观锁?
数据库管理系统(DBMS)中的并发控制的任务是确保在多个事务同时存取数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性
乐观并发控制(乐观锁)和悲观并发控制(悲观锁)是并发控制主要采用的技术手段。
在数据库管理系统中,悲观锁利用数据库本身提供的锁机制来实现的,也只有数据库层提供的锁机制才能够保证数据的排他性,否则,即使在本系统中实现那个了加锁的机制,也无法保证外部系统不会修改数据
悲观锁 1、 悲观锁概念:
悲观锁(pessimistic Lock) 顾名思义 就是很悲观,每次拿数据的时候都会认为别人会修改,每次拿数据的时候都会进行上锁,只有该事务把锁释放,其他事务才会执行与该锁冲突的操作,
2、在数据库中的加锁流程:
在对任意记录进行修改前,先尝试为该记录加上排他锁(exclusive locking)。
如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。 *
如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
其间如果有其他对该记录做修改或加排他锁的操作,都会等待我们解锁或直接抛出异常。
3、MySQL InnoDB中使用悲观锁 要使用悲观锁,必须要将mysql的自动提交,设置为手动提交
1 2 3 4 5 6 7 8 9 10 / / 0. 开始事务begin ;/ begin work;/ start transaction; (三者选一就可以)/ / 1. 查询出商品信息select status from t_goods where id= 1 for update;/ / 查询开始之前对数据库进行加锁/ / 2. 根据商品信息生成订单insert into t_orders (id,goods_id) values (null ,1 );/ / 3. 修改商品status为2 update t_goods set status= 2 ; / / 4. 提交事务commit ;/ commit work;
上面的查询语句中,我们使用了select…for update的方式,这样就通过开启排他锁的方式实现了悲观锁。此时在t_goods表中,id为1的 那条数据就被我们锁定了,其它的事务必须等本次事务提交之后才能执行。这样我们可以保证当前的数据不会被其它事务修改。
上面提到,使用select…for update会把数据给锁住,不过我们需要注意一些锁的级别,MySQL InnoDB默认行级锁。行级锁都是基于索引的,如果一条SQL语句用不到索引是不会使用行级锁的,会使用表级锁把整张表锁住,这点需要注意。
注意:只有在查询开始之前(也就是hibernate生成SQL之前)设定加锁,才会真正通过数据库的锁机制进行加锁处理。 否则,数据已经通过不包含for update的子句select sql加载进来了,所谓数据库加锁也就无从谈起。另外,for update要放到MySQL的事务中,即begin和commit中,否则不起作用。
• mysql关于锁住整个表还是锁住选中的行(主键明确,且有数据,row lock ,若无数据,无lcok 无主键,table lock 主键不明确 table lock )
例2: (无主键,table lock)
SELECT * FROM products WHERE name=’Mouse’ FOR UPDATE;
例3: (主键不明确,table lock)
SELECT * FROM products WHERE id<>’3’ FOR UPDATE;
例4: (主键不明确,table lock)
SELECT * FROM products WHERE id LIKE ‘3’ FOR UPDATE;
注1: FOR UPDATE仅适用于InnoDB,且必须在交易区块(BEGIN/COMMIT)中才能生效。
注2: 要测试锁定的状况,可以利用MySQL的Command Mode ,开二个视窗来做测试。在MySql 5.0中测试确实是这样的。
另外:MyAsim 只支持表级 innerDB支持行级锁 添加了(行级锁/表级锁)锁的数据不能被其它事务再锁定,也不被其它事务修改(修改、删除) 。是表级锁时,不管是否查询到记录,都会锁定表。 *
4、优点与不足 悲观并发控制实际上是“先取锁再访问 ”的保守策略,为数据处理的安全提供了保证。
处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会;
在只读型事务处理中由于不会产生冲突,也没必要使用锁,这样做只能增加系统负载;
会降低了并行性,一个事务如果锁定了某行数据,其他事务就必须等待该事务处理完才可以处理那行数
乐观锁 乐观锁概念: • 设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。 在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚
• 就是说各个事务都能去去拿数据,但是在最后提交数据的时候,检查一下数据的版本,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。
• 数据版本,为数据增加的一个版本标识。当读取数据时,将版本标识的值一同读出,数据每更新一次,同时对版本标识进行更新。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的版本标识进行比对,如果数据库表当前版本号与第一次取出来的版本标识值相等,则予以更新,否则认为是过期数据。
1、使用版本号实现乐观锁
使用版本号时,可以在数据初始化时指定一个版本号,每次对数据的更新操作都对版本号执行+1操作。并判断当前版本号是不是该数据的最新的版本号。
查询出商品信息
1 2 3 4 5 6 select (status,status,version) from t_goods where id=#{id} 根据商品信息生成订单 修改商品status为2 update t_goods set status=2 ,version=version+1 where id=#{id} and version=#{version};