java基础
JAVA学习
Java小知识之代码优化:
代码优化的目标是
- 减小代码的体积
- 提高代码运行的效率
1、尽量重用对象:
1、特别是String对象的使用,出现字符串连接时应该使用StringBuilder/StringBu ffer代替。由于Java虚拟机不仅要花时间生成对象,以后可能还需要花时间对这些对象进行垃圾回收和处理,因此,生成过多的对象将会给程序的性能带来很大的影响。
2、循环内不要不断创建对象引用
1 | for (int i = 1; i <= count; i++) {Object obj = new Object(); } |
这种做法会导致内存中有count份Object对象引用存在,count很大的话,就耗费内存了,建议为改为:
1 | Object obj = null;for (int i = 0; i <= count; i++) { obj = new Object(); } |
内存中只有一份Object对象引用,每次new Object()的时候,Object对象引用指向不同的Object罢了,但是内存中只有一份,这样就大大节省了内存空间了
3、 尽量使用HashMap、ArrayList、StringBuilder,除非线程安全需要,否则不推荐使用Hashtable、Vector、StringBuffer,后三者由于使用 同步机制而导致了性能开销
4、实现RandomAccess接口的集合比如ArrayList,应当使用最普通的for循环而不是foreach循环来遍历
这是JDK推荐给用户的。JDK API对于RandomAccess接口的解释是:实现RandomAccess接口用来表明其支持快速随机访问,此接口的主要目的是允许一般的算法更改其行为,从而将其应用到随机或连续访问列表时能提供良好的性能。实际经验表明,实现RandomAccess接口的类实例,假如是随机访问的,使用普通for循环效率将高于使用foreach循环;反过来,如果是顺序访问的,则使用Iterator会效率更高。可以使用类似如下的代码作判断:``
1 | if (list instanceof RandomAccess) |
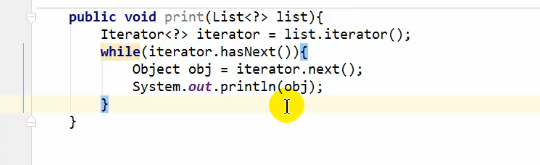
foreach循环的底层实现原理就是迭代器Iterator,
参见Java语法糖1:可变长度参数以及foreach循环原理。所以后半句反过来,如果是顺序访问的,则使用Iterator会效率更高”的意思就是顺序访问的那些类实例,使用foreach循环去遍历。
Java判断字符串是否为空
一.空字符串与null区别
1、类型
null表示的是一个对象的值,而并不是一个字符串。例如声明一个对象的引用,String a = null ;
“”表示的是一个空字符串,也就是说它的长度为0。例如声明一个字符串String str = “” ;
2、内存分配
String str = null ; 表示声明一个字符串对象的引用,但指向为null,也就是说还没有指向任何的内存空间;
String str = “”; 表示声明一个字符串类型的引用,其值为””空字符串,这个str引用指向的是空字符串的内存空间;
在java中变量和引用变量是存在栈中(stack),而对象(new产生的)都是存放在堆中(heap):
就如下:
String str = new String(“abc”) ;
ps:=左边的是存放在栈中(stack),=右边是存放在堆中(heap)。
3、示例程序:
1 | public class String_Demo01 { |
通过如上的程序可以得出如下结论:
字符串对象与null的值不相等,且内存地址也不相等;
空字符串对象与null的值不相等,且内存地址也不相等;
new String()创建一个字符串对象的默认值为”” (String类型成员变量的初始值为null)
4.Java判断字符串常方法
方法一: 最多人使用的一个方法, 直观, 方便, 但效率很低:
if(s == null || s.equals(""));
方法二: 比较字符串长度, 效率高, 是我知道的最好一个方法:
if(s == null || s.length() == 0);
方法三: Java SE 6.0 才开始提供的方法, 效率和方法二几乎相等, 但出于兼容性考虑, 推荐使用方法二.
if(s == null || s.isEmpty());
方法四: 这是一种比较直观,简便的方法,而且效率也非常的高,与方法二、三的效率差不多:
if (s == null || s == "");
注意:s == null 是有必要存在的.
如果 String 类型为null, 而去进行 equals(String) 或 length() 等操作会抛出java.lang.NullPointerException.
并且s==null 的顺序必须出现在前面,不然同样会抛出java.lang.NullPointerException.
如下Java代码:
1 | String str = null; |
五、StringUtils的isBlank与isEmply
1.public static boolean isEmpty(String str)
判断某字符串是否为空,为空的标准是 str==null 或 str.length()==0
下面是 StringUtils 判断是否为空的示例:
1 | StringUtils.isEmpty(null) = true |
2.public static boolean isNotEmpty(String str)
判断某字符串是否非空,等于 !isEmpty(String str)
下面是示例:
1 | StringUtils.isNotEmpty(null) = false |
3.pblic static boolean isBlank(String str)
判断某字符串是否为空或长度为0或由空白符(whitespace) 构成
下面是示例:
1 | StringUtils.isBlank(null) = true StringUtils.isBlank("") = true StringUtils.isBlank(" ") = true StringUtils.isBlank(" ") = true StringUtils.isBlank("\t \n \f \r") = true //对于制表符、换行符、换页符和回车符 StringUtils.isBlank() //均识为空白符 StringUtils.isBlank("\b") = false //"\b"为单词边界符 StringUtils.isBlank("bob") = false StringUtils.isBlank(" bob ") = false |
4.public static boolean isNotBlank(String str)
判断某字符串是否不为空且长度不为0且不由空白符(whitespace) 构成,等于 !isBlank(String str)
下面是示例:
1 | StringUtils.isNotBlank(null) = false StringUtils.isNotBlank("") = false StringUtils.isNotBlank(" ") = false StringUtils.isNotBlank(" ") = false StringUtils.isNotBlank("\t \n \f \r") = false StringUtils.isNotBlank("\b") = true StringUtils.isNotBlank("bob") = true StringUtils.isNotBlank(" bob ") = true |
java list如何进行判断空
1、常用表达方式
1 | if(null == list || list.size() ==0 ){ //为空的情况}else{ //不为空的情况} |
1 | if(list!=null && !list.isEmpty()){ //不为空的情况}else{ //为空的情况} |
2、遇到问题
1、 list.isEmpty() 和 list.size()==0
答案:没有区别 。isEmpty()判断有没有元素,而size()返回有几个元素, 如果判断一个集合有无元素 建议用isEmpty()方法.比较符合逻辑用法。
2、 list!=null 跟 ! list.isEmpty()
这就相当与,你要要到商店买东西
list!=null 首先判断是否有商店
!list.isEmpty() 没有判断商店是否存在,而是判断商店是否有东西
Java局部变量、成员变量、类变量
1、实例变量
也叫对象变量、类成员变量:从属于类,并由类生生成对象是,才分配存储空间, 能通过对象访问实例变量
1 | private String nameString; public int age; protected int priority; //实例方法 public String getNameString(){ return this.nameString; } |
类变量:
也叫静态变量,是一种比较特殊的实例变量,用static关键字修饰;一个类的静态变量,所有由这类生成的对象都共用这个类变量,类装载时就分配存储空间。一个对象修改了变量,则所以对象中这个变量的值都会发生改变。
1 | //类变量(静态变量) public static int a = 0; //实例变量 private String nameString; |
局部变量:
方法中或者某局部中声明定义的变量方法或方法的参数 ,他们只存在创建他们的block里无法再block外面进行任何操作,在Java的多线程中,每个线程都会复制一份局部的变量,可以防止某些同步问题的发生
1 | public static int a = 0; //实例变量 private String nameString; public void test(){ //局部变量 int temp = 1; |
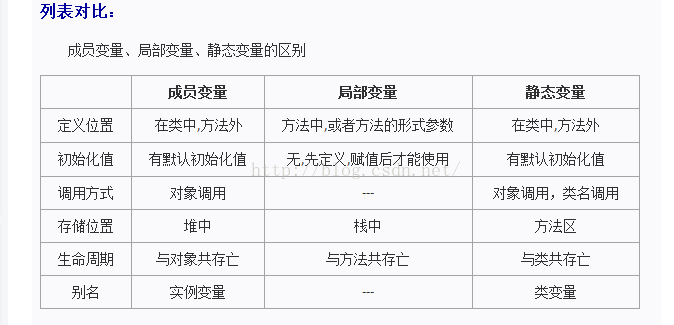
四、他们的区别
成员变量和局部变量的区别
成员变量:
①成员变量定义在类中,在整个类中都可以被访问。
②成员变量随着对象的建立而建立,随着对象的消失而消失,存在于对象所在的堆内存中。
③成员变量有默认初始化值。
局部变量:
①局部变量只定义在局部范围内,如:函数内,语句内等,只在所属的区域有效。
②局部变量存在于栈内存中,作用的范围结束,变量空间会自动释放。
③局部变量没有默认初始化值
在使用变量时需要遵循的原则为:就近原则
首先在局部范围找,有就使用;接着在成员位置找
b 成员变量和静态变量的区别
1、两个变量的生命周期不同
成员变量随着对象的创建而存在,随着对象被回收而释放。
静态变量随着类的加载而存在,随着类的消失而消失。****
2、调用方式不同
成员变量只能被对象调用。
静态变量可以被对象调用,还可以被类名调用。
3、别名不同
成员变量也称为实例变量。
静态变量也称为类变量。
4、数据存储位置不同
成员变量存储在堆内存的对象中,所以也叫对象的特有数据。
静态变量数据存储在方法区(共享数据区)的静态区,所以也叫对象的共享数据。
[java 静态变量生命周期(类生命周期) - HF_Cherish - 博客园 (cnblogs.com)](https://www.cnblogs.com/hf-cherish/p/4970267.html#:~:text=因为静态变量生命周期虽然长(就是类的生命周期),但是当程序执行完,也就是该类的所有对象都已经被回收,或者加载类的ClassLoader已经被回收,那么该类就会从jvm的方法区卸载,即生命期终止。 更进一步来说,static变量终究是存在jvm的内存中的,jvm下次重新运行时,肯定会清空里边上次运行的内容,包括方法区、常量区的内容。,要实现某些变量在程序多次运行时都可以读取,那么必须要将变量存下来,即存到本地文件中。 常用的数据存取格式:XML、JSON、Propertities类(类似map的键值对)等)
java序列化:
一、序列化的含义、意义及使用场景:
序列化:将对象写入到IO流中
反序列化:从IO流中恢复对象
序列化目的:
方便数据的传递以及存储到磁盘上(把一个Java对象写入到硬盘或者传输到网路上面的其它计算机,这时我们就需要将对象转换成字节流才能进行网络传输。对于这种通用的操作,就出现了序列化来统一这些格式)
简单来说序列化就是一种用来处理对象流的机制。将对象转化成字节序列后可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
就是说你想要你要传输对象,那么就必须转换字节码传输,传输之后想要还原到原来的样子,就必须是要进行
使用场景:
- 所有可在网络上传输的对象都必须是可序列化的,比如RMI(remote method invoke,即远程方法调用),传入的参数或返回的对象都是可序列化的,否则会出错
- 所有需要保存到磁盘的java对象都必须是可序列化的, Redis 将对象当做字符串存储的时候,如果对象实现了序列化,则只需要将对象直接存储即可(java会自动将对象转换成序列化后的字节流)
二、为什么要序列化和反序列化
我们知道,当两个进程进行远程通信时,可以相互发送各种类型的数据,包括文本、图片、音频、视频等, 而这些数据都会以二进制序列的形式在网络上传送。那么当两个Java进程进行通信时,能否实现进程间的对象传送呢?答案是可以的。如何做到呢?这就需要Java序列化与反序列化了。换句话说,一方面,发送方需要把这个Java对象转换为字节序列,然后在网络上传送;另一方面,接收方需要从字节序列中恢复出Java对象。当我们明晰了为什么需要Java序列化和反序列化后,我们很自然地会想Java序列化的好处。
- 实现了数据的持久化,通过序列化可以把数据永久地保存到硬盘上(通常存放在文件里)
- 利用序列化实现远程通信,即在网络上传送对象的字节序列。
三、涉及到的javaAPI
java.io.ObjectOutputStream表示对象输出流,它的writeObject(Object obj)方法可以对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
java.io.ObjectInputStream表示对象输入流,它的readObject()方法源输入流中读取字节序列,再把它们反序列化成为一个对象,并将其返回。
只有实现了Serializable或Externalizable接口的类的对象才能被序列化,否则抛出异常。
转载:
java序列化,看这篇就够了 - 9龙 - 博客园 (cnblogs.com)
(66条消息) java序列化和反序列化以及序列化ID的作用分析_Java仗剑走天涯的博客-CSDN博客_序列化id
通常建议:程序创建的每个JavaBean类都实现Serializeable接口
String类型
关于String 不可以变:
什么是不可变?
说String不可以变,那么到底是什么不可以变呢? 我们可以这样认为,当创建一个对象,不改变他的状态,就是说不能改变他的成员变量,包括基本类型的值不能变,引用类型的不能指向别的对象,它的状态也不能够被改变
例如一下状态:
1 | String s = "ABCabc"; |
不是说不可变了吗,为什么还是变了?
这个就要注意一下, s只是String对象的一个引用,并不是指对象本身,。对象在内存中是一个内存区,成员变量越多,内存就越大。引用只是一个四字节的地址,通过该地址可以访问到对象。所以说 s只是一个引用,它指向了对象所处的地址。代码中,s是同一引用,但是,值在不同的地址中,开始时,引用s 是“ABC”,调用同一个引用,又将s指向的地址改变成了“123456”的值
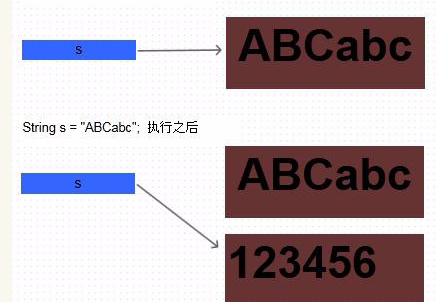
在Java中,Java并不能直接操控对象本身,所有的对象都是一个应用的指向,必须通过引用才能访问对象的本身,包括成员变量等,改变对象的成员变量,调用指针的方法等,引用和指针类似,都是存放的对象在内存中的地址,只是不能够进行指针运算

所以说,一旦创建就不能够修改,而是重新创建一个地址,然后让该引用指向该地址的值,原来的数据并没有变化。而是重新创建了一个新的地址,改变了引用的指向
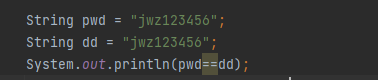
上面的结果是true,因为string在创建对象是,在常量池里边,创建一个对象,会自动到常量池里面去找,如果有改变该引用的指向,否则,重新创建一个对象
==比较的是值是不是相同,这个值分为地址值和数据的值,但它是基本数据类型时(int等 但是并没有对他进行实例化),因为那么就是比较的值,如果两个引用变量,指向同一个地址,采用== 就是ture,
equals 没有重写之前,就是和==一样
打个方,拿string做个比较就是,它重写了equals方法,两个string引用变量去比较,首先比较采用== ,比较地址值,你的地址值指向一样,那值肯定就是相等的
如果在不同的地址,那么引用地址的引用类型就需要重写了,equals来比较是否连个对象中的值相同
1 | public boolean equals(Object anObject) { |
1 | .junit.Test |
如何理解 String 类型值的不可变? - 知乎 (zhihu.com)
关于hashcode ():
什么是hash :
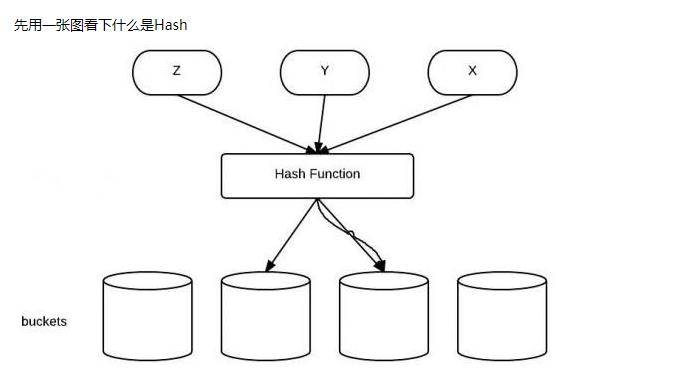
- 不同关键字经过散列算法变换后可能得到同一个散列地址,这种现象称为碰撞
- 如果两个Hash值不同(前提是同一Hash算法),那么这两个Hash值对应的原始输入必定不同
HashCode:
1、HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的
2、如果两个对象equals相等,那么这两个对象的HashCode一定也相同
3、如果对象的equals方法被重写,那么对象的HashCode方法也尽量重写
4、如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置
HashCode有什么用
回到最关键的问题,HashCode有什么用?不妨举个例子:
1、假设内存中有0 1 2 3 4 5 6 7 8这9个位置,如果我有个字段叫做ID,那么我要把这个字段存放在以上9个位置之一,如果不用HashCode而任意存放,那么当查找时就需要到8个位置中去挨个查找
2、使用HashCode则效率会快很多,把ID的HashCode % 9,然后把ID存放在取得余数的那个位置,然后每次查找该类的时候都可以通过ID的HashCode % 9求余数直接找到存放的位置了
3、如果ID的HashCode % 9算出来的位置上本身已经有数据了怎么办?这就取决于算法的实现了,比如ThreadLocal中的做法就是从算出来的位置向后查找第一个为空的位置,放置数据;HashMap的做法就是通过链式结构连起来。反正,只要保证放的时候和取的时候的算法一致就行了。
4、如果ID的HashCode % 9相等怎么办(这种对应的是第三点说的链式结构的场景)?
这时候就需要定义equals了。先通过HashCode%9来判断类在哪一个位置,再通过equals来在这个位置上寻找需要的类。对比两个类的时候也差不多,先通过HashCode比较,假如HashCode相等再判断equals。如果两个类的HashCode都不相同,那么这两个类必定是不同的。
举个实际的例子Set:
我们知道Set里面的元素是不可以重复的,那么如何做到?
Set是根据equals()方法来判断两个元素是否相等的。比方说Set里面已经有1000个元素了,那么第1001个元素进来的时候,最多可能调用1000次equals方法,如果equals方法写得复杂,对比的东西特别多,那么效率会大大降低。使用HashCode就不一样了,比方说HashSet,底层是基于HashMap实现的,先通过HashCode取一个模,这样一下子就固定到某个位置了,如果这个位置上没有元素,那么就可以肯定HashSet中必定没有和新添加的元素equals的元素,就可以直接存放了,都不需要比较;如果这个位置上有元素了,逐一比较,比较的时候先比较HashCode,HashCode都不同接下去都不用比了,肯定不一样,HashCode相等,再equals比较,没有相同的元素就存,有相同的元素就不存。如果原来的Set里面有相同的元素,只要HashCode的生成方式定义得好(不重复),不管Set里面原来有多少元素,只需要执行一次的equals就可以了。这样一来,实际调用equals方法的次数大大降低,提高了效率。
为什么要重写hashcode
[讲讲HashCode的作用 - 五月的仓颉 - 博客园 (cnblogs.com)](https://www.cnblogs.com/xrq730/p/4842028.html#:~:text=HashCode. 然后讲下什么是HashCode,总结几个关键点:.,1、HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的. 2、如果两个对象equals相等,那么这两个对象的HashCode一定也相同. 3、如果对象的equals方法被重写,那么对象的HashCode方法也尽量重写.)
(6条消息) 为什么重写equals()方法时,必须要求重写hashCode()方法?_IT无知君的博客-CSDN博客
保证成员变量都相等的情况下,他们的hashcode都相等的,重写equals方法必须尽量要重写hashCode方法的原因
1.equals()相等的两个对象他们的hashCode()肯定相等,也就是用equals()对比是绝对可靠的。
2.hashCode()相等的两个对象他们的equals()不一定相等,也就是hashCode()不是绝对可靠的。
所有对于需要大量并且快速的对比的话如果都用equals()去做显然效率太低,所以解决方式是,每当需要对比的时候,首先用hashCode()去对比,如果hashCode()不一样,则表示这两个对象肯定不相等(也就是不必再用equals()去再对比了),如果hashCode()相同,此时再对比他们的equals(),如果equals()也相同,则表示这两个对象是真的相同了,这样既能大大提高了效率也保证了对比的绝对正确性!
1 | public int hashCode() { |
java关键字
1、instanceof
1、instanceof用法详解:
instanceof严格上来说是一个双目运算符,用来测试一个类是否是一个类的实例
1 | boolean result = obj instanceof Class |
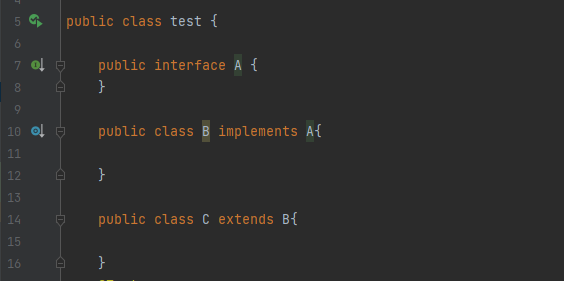
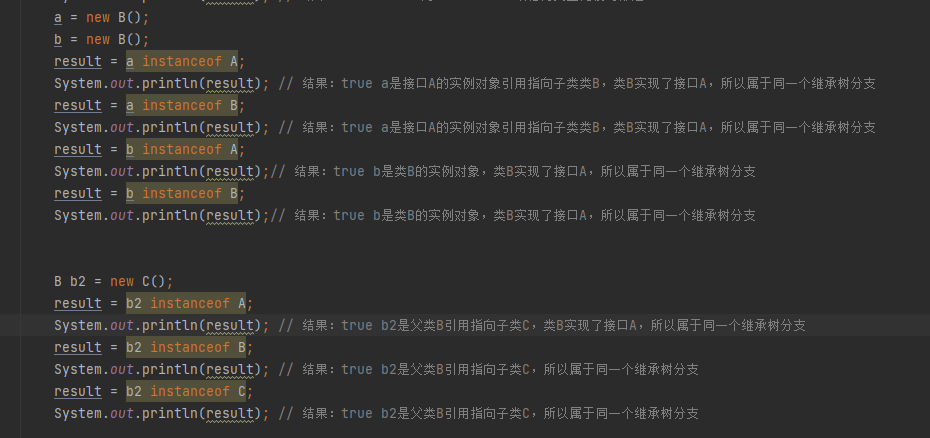
- 类的实例包含本身的实例,以及所有直接或间接子类的实例
- instanceof左边显式声明的类型与右边操作元必须是同种类或存在继承关系,也就是说需要位于同一个继承树,否则会编译错误
2、instanceof用法:
- 左边的实例对象不能为基本数据类型

- 左边的实例与右边的类不在同一个继承树上
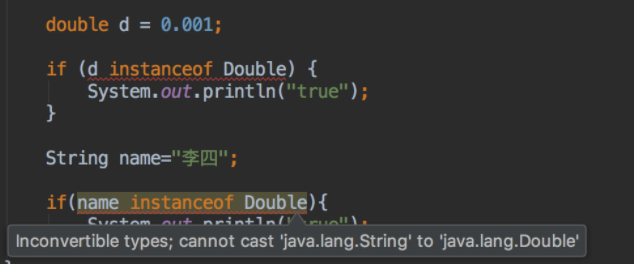
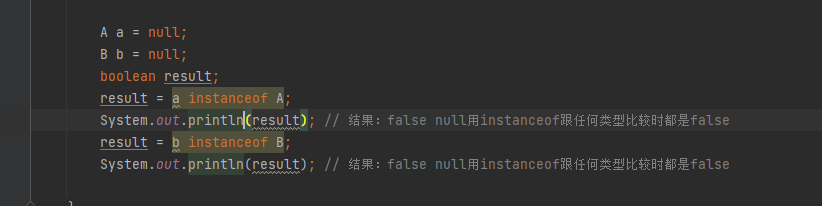
- obj 为 null ,跟任何类型比较时都是false
obj 为 class 接口的实现类
1
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
instanceof 运算符判断 某个对象是否是 List 接口的实现类,如果是返回 true,否则返回 false

obj 为 class 类的直接或间接子类
3、原理使用伪代码表示为:

表达式必须是null或者是引用类型,否则会返回false
如果 obj 不为 null 并且 (T) obj 不抛 ClassCastException 异常则该表达式值为 true ,否则值为 false 。
4、应用场景:
对象类型强制转换:
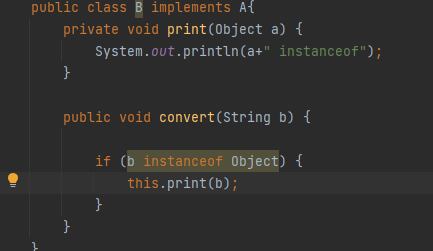

final关键字:
[浅析Java中的final关键字 - Matrix海子 - 博客园 (cnblogs.com)](https://www.cnblogs.com/dolphin0520/p/3736238.html#:~:text=一.final关键字的基本用法. 在Java中,final关键字可以用来修饰类、方法和变量(包括成员变量和局部变量)。. 下面就从这三个方面来了解一下final关键字的基本用法。. 当用final修饰一个类时,表明这个类不能被继承。.,也就是说,如果一个类你永远不会让他被继承,就可以用final进行修饰。. final类中的成员变量可以根据需要设为final,但是要注意final类中的所有成员方法都会被隐式地指定为final方法。. 在使用final修饰类的时候,要注意谨慎选择,除非这个类真的在以后不会用来继承或者出于安全的考虑,尽量不要将类设计为final类。. 下面这段话摘自《Java编程思想》第四版第143页:.)
static 关键字:
目的:
当只想用一个内存区去保存一个特定的数据(无论创建多少个对象,甚至根本不用去创建对象)
与该类没有任何的对象的关联,即使没有创建对象,也能够调用方法
特点:
static修饰的代码块、变量、方法内部类在类加载的期间就已经完成了初始化,存储在堆中的静态存储区,static优于对象而存在
static修饰的(变量和成员方法)被所有的对象所共享,也叫静态变量或静态方法
使用场景:
static 是一个修饰符,常常用来修饰变量和方法,如在开发过程中常常static 来进行修饰,如 工具类的方法,如DateUtils,StringUtils这类的工具方法会用到static来进行修饰
static 变量
static 方法
static 代码块
static 内部类
static 包内导入
static变量:
随着类的加载而存在,随着类的消失而消失,当类被加载的时候,就会在Java heap中分配内存空间,静态变量被所有的 对象 进行共享,一个值改动,就会改变另一个对象的取值。
1 | public class Person { |
什么时候使用static变量
作为共享变量去使用,通过常和final关键字使用:
1 | private static final String GENERAL_MAN = "man"; |
减少对象的创建,比如在类开头的部分,定义Logger方法,用于异常日志采集:
1 | private static Logger LOGGER = LogFactory.getLoggger(MyClass.class); |
static方法:
静态方法只能访问静态成员或静态方法
非静态方法既可以访问静态方法也可以访问非静态方
什么时候使用static方法:
static方法一般用于与当前对象无法的工厂方法、工具方法。如Math.sqrt(),Arrays.sort(),StringUtils.isEmpty()等。
static 代码块:
static代码块在加载一个类的时候最先执行,且只执行一次。
1 | public static Map<String, String> timeTypes; |
JAVA集合:
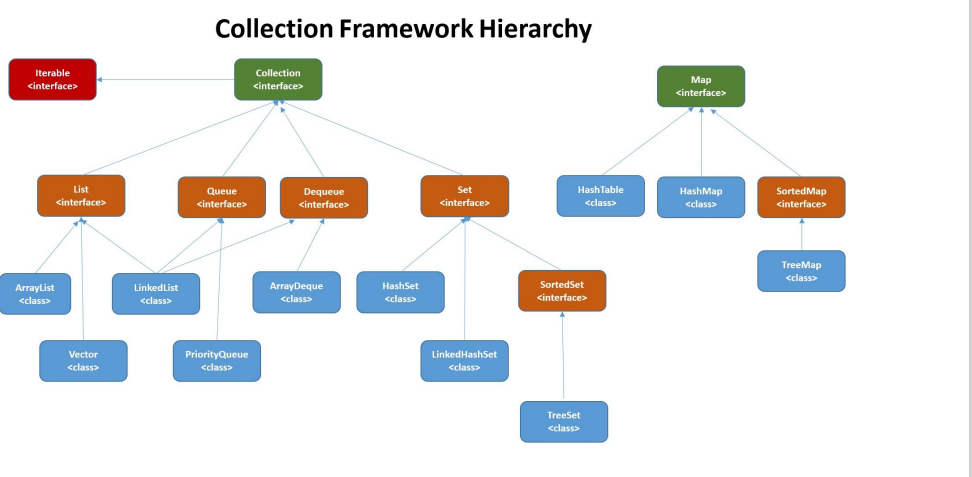
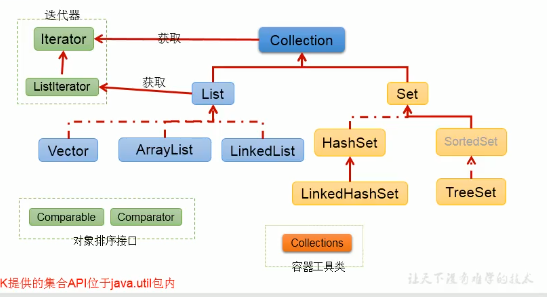

集合框架底层数据结构总结
List
Arraylist : Object[] 数组
Vector : Object[] 数组
LinkedList : 双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)
Set
HashSet (⽆序,唯⼀): 基于 HashMap 实现的,底层采⽤ HashMap 来保存元素
LinkedHashSet : LinkedHashSet 是 HashSet 的⼦类,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的 LinkedHashMap 其内部是基于 HashMap 实现⼀样,不过还是有⼀点点区别的
TreeSet (有序,唯⼀): 红⿊树(⾃平衡的排序⼆叉树) 再来看看 Map 接⼝下⾯的集合。
Map
HashMap : JDK1.7 之前 HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突⽽存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较⼤的变化,当链表⻓度⼤于阈值(默认为 8)(将链表转换成红⿊树前会判断,如果当前数组的⻓度⼩于 64,那么会选择先进⾏数组扩容,⽽不是转换为红⿊树)时,将链表转化为红⿊树,以 减少搜索时间
LinkedHashMap : LinkedHashMap 继承⾃ HashMap ,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红⿊树组成。另外, LinkedHashMap 在上⾯结构的基础上,增加了 ⼀条双向链表,使得上⾯的结构可以保持键值对的插⼊顺序。同时通过对链表进⾏相应的操作, 实现了访问顺序相关逻辑。详细可以查看:《LinkedHashMap 源码详细分析(JDK1.8)》
Hashtable : 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突 ⽽存在的
TreeMap : 红⿊树(⾃平衡的排序⼆叉树)
如何选⽤集合?
主要根据集合的特点来选⽤
根据键值获取到元素值时就选⽤ Map 接⼝下的集合
- 需要排序时选择 TreeMap
- 不需要排序时就选择 HashMap
- 需要保证线程安全就选⽤ ConcurrentHashMap 。
只需要存放元素值: 选择实现 Collection 接⼝的集合
保证元素唯⼀: Set 接⼝的集合⽐如 TreeSet 或 HashSet ,不需要就选择实现 List 接⼝的⽐如 ArrayList 或 LinkedList
有哪些集合是线程不安全的?怎么解决呢?
我们常⽤的 Arraylist , LinkedList , Hashmap , HashSet , TreeSet , TreeMap , PriorityQueue 都不是线程安全的。
解决办法很简单,可以使⽤线程安全的集合来代替。 如果你要使⽤线程安全的集合的话,
java.util.concurrent 包中提供了很多并发容器供你使⽤:
- ConcurrentHashMap : 可以看作是线程安全的
- CopyOnWriteArrayList :可以看作是线程安全的 ArrayList ,在读多写少的场合性能⾮常好,远远好于 Vector
- ConcurrentLinkedQueue :⾼效的并发队列,使⽤链表实现。可以看做⼀个线程安全的 LinkedList ,这是⼀个⾮阻塞队列。
- BlockingQueue : 这是⼀个接⼝,JDK 内部通过链表、数组等⽅式实现了这个接⼝。表示阻塞队列,⾮常适合⽤于作为数据共享的通道。
- ConcurrentSkipListMap :跳表的实现。这是⼀个 Map ,使⽤跳表的数据结构进⾏快速查找。
Collection 接口
- Collection 接口是 List、Set 和 Queue 接口的父接口,该接口里定义的方法 既可用于操作 Set 集合,也可用于操作 List 和 Queue 集合。
- JDK不提供此接口的任何直接实现,而是提供更具体的子接口(如:Set和List) 实现。
- 在 Java5 之前,Java 集合会丢失容器中所有对象的数据类型,把所有对象都 当成 Object 类型处理;从 JDK 5.0 增加了泛型以后,Java 集合可以记住容器中对象的数据类型。
Collection 接口方法
1、添加
- add(Object obj)
- addAll(Collection coll)
2、获取有效元素的个数
- int size()
3、清空集合
- void clear()
4、是否是空集合
- boolean isEmpty()
5、是否包含某个元素
- boolean contains(Object obj):是通过元素的equals方法来判断是否 是同一个对象
- boolean containsAll(Collection c):也是调用元素的equals方法来比 较的。拿两个集合的元素挨个比较。
6、删除
- boolean remove(Object obj) :通过元素的equals方法判断是否是 要删除的那个元素。只会删除找到的第一个元
- 素 boolean removeAll(Collection coll):取当前集合的差集
7、取两个集合的交集
- boolean retainAll(Collection c):把交集的结果存在当前集合中,不影响c
8、集合是否相等
- boolean equals(Object obj)
9、转成对象数组
- Object[] toArray()
10、获取集合对象的哈希值 hashCode()
11、遍历
iterator():返回迭代器对象,用于集合遍历
Iterator迭代器接口
使用 Iterator 接口遍历集合元素

Iterator接口的方法


在调用it.next()方法之前必须要调用it.hasNext()进行检测。若不调用,且 下一条记录无效,直接调用it.next()会抛出NoSuchElementException异常。
Iterator接口remove()方法
1 | Iterator iter = coll.iterator();//回到起点 |
1 | Map<Integer, String> map = new HashMap(); |
Iterator可以删除集合的元素,但是是遍历过程中通过迭代器对象的remove方法,不是集合对象的remove方法。
如果还未调用next()或在上一次调用 next 方法之后已经调用了 remove 方法, 再调用remove都会报IllegalStateException。
foreach 循环遍历集合元素:

1.2. Collection 子接口
List接口:
1.2.1: 什么是List:
List: 元素是有序的(元素存取是有序)、可重复. 有序的 collection,可以对列表中每个元素的插入位置进行精确地控制。可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。可存放重复元素,元素存取是有序的。
常用实现类:
ps**:dancer: ArrayList、LinkedList和Vector。**
- ArrayList
线程不安全的,效率高;底层使用Object[]
- LinkedList
对于频繁的插入、删除操作,使用此类效率比ArrayList高;双链表
- Vector
作为List接口的古老实现类;线程安全的,效率低;底层使用object[]
1.2.2: List接口中常用类:
List除了从Collection集合继承的方法外,List 集合里添加了一些根据索引来 操作集合元素的方法。
- void add(int index, Object ele):在index位置插入ele元素
- boolean addAll(int index, Collection eles):从index位置开始将eles中 的所有元素添加进来
- Object get(int index):获取指定index位置的元素
- int indexOf(Object obj):返回obj在集合中首次出现的位置
- int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置
- Object remove(int index):移除指定index位置的元素,并返回此元素
- Object set(int index, Object ele):设置指定index位置的元素为ele
- List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex 位置的子集合
1.2.3:ArrayList
简介:
底层数据: 底层是数组。与数组相比较,容量能够动态增长。在添加大量数组前,ensureCapacity操作数组的容量。可以减少递增式的分类
插入和删除:线性表顺序存储,插入元素的时间复杂度为O(n),移动到指定元素再插入,取第i元素时间复杂度为O(1)
是否支持快速随机访问:实现了RandomAccess 接口, RandomAccess 是一个标志接口,表明实现这个这个接 口的 List 集合是支持快速随机访问的。在 ArrayList 中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。
ArayList 实现了Cloneable 接口,即覆盖了函数 clone(),能被克隆。 ArrayList 实现java.io.Serializable 接口,这意味着ArrayList支持序列化,能通过序列化去传输。
线程安全:操作不是线程安全的
建议在单线程中才使用 ArrayList, 而在多线程中可以选择 Vector 或者 CopyOnWriteArrayList。
为什么扩容:
ArrayList的扩容机制提高了性能,如果每次只扩充一个, 那么频繁的插入会导致频繁的拷贝,降低性能,而ArrayList的扩容机制避免了这种情况。
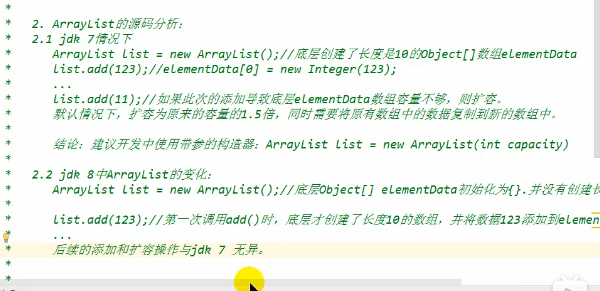
- jdk7中的ArrayList的对象创建的类似于单例的饿汉模式,开始创建的时候就分配内存地址
- jdk8中的ArrayList的对象中的类似于单例模式的懒汉式,延迟了数组的创建,需要的时候在进行创建
源码分析:
JDK1.7:
ArrayList 提供了三种方式的构造器,可以构造一个默认初始容量为 10 的空列表、构造 一个指定初始容量的空列表以及构造一个包含指定 collection 的元素的列表,这些元素按照 该 collection 的迭代器返回它们的顺序排列的。
1 | public ArrayList() { |
数组扩容:
1 | public void ensureCapacity(int minCapacity) { |
数组进行扩容时,会将老数组中的元素重新拷贝一份到新的 数组中,每次数组容量的增长大约是其原容量的 1.5 倍。这种操作的代价是很高的,因此在 实际使用时,我们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时, 要在构造 ArrayList 实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求, 通过调用 ensureCapacity 方法来手动增加 ArrayList 实例的容量。
JDK 1.8
思路:
JDK 1.8扩容的机制为,ArrayList在初始化时没有进行初始化默认赋值,而是赋予空的数组,无参构造时使用的空数组,有参创建一个该范围的数组,在添加函数中,如果开始时,小于10.初始化为10,但最小的minCapacity 大于了 数组长度,就需要进行扩容,扩容机制为原来的1.5 倍,如果扩容之后还是比原来的数据小,那就是原来的数据 ,超过则指定为Integer的最大值,否则指定为限制容量大小,之后复制元素
1 | /** |
1 |
|
得到最小的扩容量
1 |
|
判断是否需要进行扩容(如果初始值为10,那么直到添加到11 个元素才需要进行扩容):
1 | //判断是否需要扩容 |
扩容函数grow():
1 | /** |
移位运算符
简介:
移位运算符就是在二进制的基础上对数字进行平移。按照平移的方向和填充数字的规则分为三种: <<(左移)、>>(带符号右移)和>>>(无符号右移)。
作用:
对于大数据的2进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而 已,不去计算,这样提高了效率,节省了资源
比如这里:int newCapacity = oldCapacity + (oldCapacity >> 1);
右移一位相当于除2,右移n位相当于除以 2 的 n 次方。
这里 oldCapacity 明显右移了1位所以相当于 oldCapacity /2。
ps:jack_o_lantern:另外需要注意的是:
java 中的length 属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性.
java 中的length()方法是针对字 符串String说的,如果想看这个字符串的长度则用到 length()这个 方法. java 中的size()方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看
1 | package list; |
1 | // toArray用法 |
LinkedList(双向链表):
简介:
底层双向链表:****实现了List接口和Deque接口的双端链表
高效删除插入:LinkedList底层的链表结构使它支持高效的插入和删除操作,另外它实现了Deque接口,使得 LinkedList类也具有队列的特性;
LinkedList不是线程安全的,如果想使LinkedList变成线程安全的,可以调用静态类Collections类中的 synchronizedList方法:
1 | List list=Collections.synchronizedList(new LinkedList()) |

内部结构:
LinkedList类中的一个内部私有类Node
1 | private static class Node<E> { |
Arraylist 与 LinkedList 区别?
是否保证线程安全:
ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
底层数据结构:
- Arraylist 底层使⽤的是 Object 数组;
- LinkedList 底层使⽤的是双向链表数据结构
- (JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下⾯有介绍到!)
插⼊和删除是否受元素位置的影响:
① ArrayList 采⽤数组存储,所以插⼊和删除元素的 时间复杂度受元素位置的影响。 ⽐如:执⾏ add(E e) ⽅法的时候, ArrayList 会默认在 将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。
但是如果要在指定位置 i 插⼊和删除元素的话( add(int index, E element) )
**时间复杂度就为 O(n-i)**。
因为在进⾏上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执⾏向后位/向前移⼀位的操作。
② LinkedList 采⽤链表存储,所以对于 add(E e) ⽅法的插⼊,删除元素时间复杂度不受元素位置的影响,近似 O(1),
如果是要在指定位置 i 插⼊和删除元素的话( (add(int index, E element) ) 时间复杂度近似为 o(n)) 因为需要先移动到指定位置再插⼊。
是否⽀持快速随机访问:
LinkedList 不⽀持⾼效的随机元素访问,⽽ ArrayList ⽀持。 快速随机访问就是通过元素的序号快速获取元素对象(对应于 get(int index) ⽅法)。
内存空间占⽤:
ArrayList 的空间浪费主要体现在在 list 列表的结尾会预留⼀定的容量空间,⽽ LinkedList 的空间花费则体现在它的每⼀个元素都需要消耗⽐ ArrayList 更多的空间 (因为要存放直接后继和直接前驱以及数据)。
双向链表:
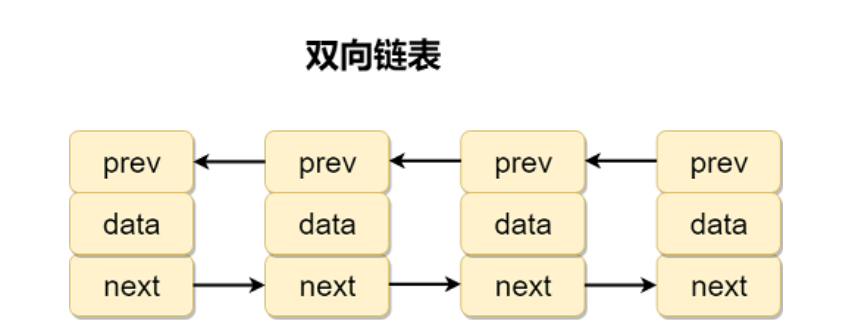
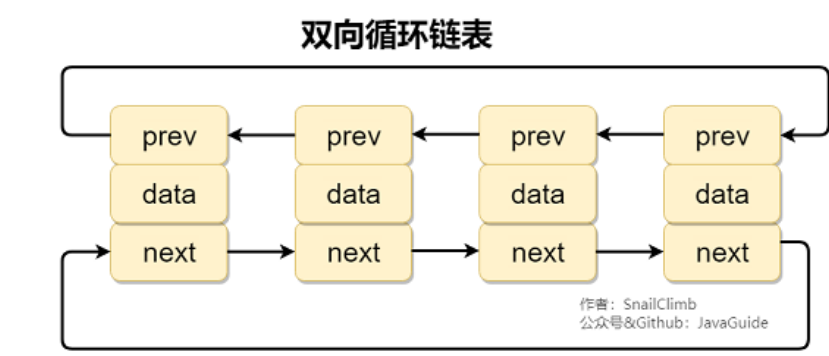
双向循环链表: 最后⼀个节点的 next 指向 head,⽽ head 的 prev 指向最后⼀个节点,构成⼀个 环。
vector:
ArrayList和Vector的区别
Vector和ArrayList几乎是完全相同的,唯一的区别在于Vector是同步类(synchronized),属于强同步类。因此开销就比ArrayList要大,访问要慢
Vector每次扩容请求其大小的2倍空间,而ArrayList是1.5倍。Vector还有一个子类Stack。
Set接口:
什么是set
存储无序的、不可重复的对象:
- HashSet 是set接口的典型的实例,大多数使用Set集合都是
- 按hash算法来存储集合中的元素,具有很好的存储、删除、查找、删除的性能
⽆序性和不可重复性的含义是什么
- 1、什么是⽆序性?
⽆序性不等于随机性 ,⽆序性是指存储的数据在底层数组中并⾮按照数组索引的顺序添加 ,⽽是根据数据的哈希值决定的。
- 2、什么是不可重复性?
不可重复性是指添加的元素按照 equals()判断时 ,返回 false,需要同时重写 equals()⽅法和 HashCode()⽅法。
特点
- 不能够保证元素的排列的顺序
- HashSet不是线程安全的
- 集合的元素可以为空值
判断两个元素相等的标准,通过hashcode()方法比较,并且两个对象的quals()方法也相同
对于存放在Set容器中的对象,对应的类一定要重写equals()和hashCode(Object obj)方法,以实现对象相等规则。即:“相等的对象必须具有相等的散列码”。
⽐较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
- HashSet 是 Set 接⼝的主要实现类 ,HashSet 的底层是 HashMap,线程不安全的,可以存储 null 值;
- LinkedHashSet 是 HashSet 的⼦类,能够按照添加的顺序遍历;
- TreeSet 底层使⽤红⿊树,能够按照添加元素的顺序进⾏遍历,排序的⽅式有⾃然排序和定制排序
HashSet:
线程不安全,内部是基于散列函数实现,存取速度快。它是如何保证元素唯一性的呢?依赖的是元素的hashCode方法和euqals方法。
底层是HashMap

先进行hash值比较,在进行equals比较
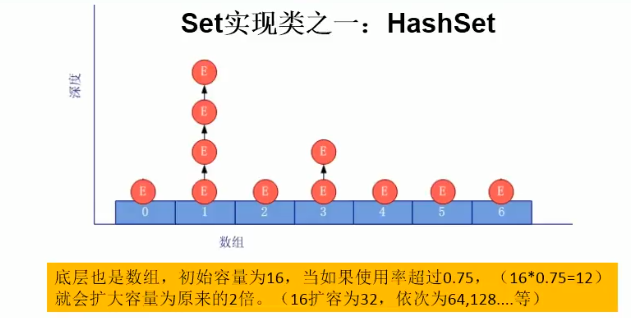
HashCode:


1 |
|
TreeSet:
基本简介
按照对象的不同属性进行排序
两种排序:自然排序,定制排序
重写排序之后,如果你直接添加元素,会进行自动排序,下面是二级排序,如果有一个属性相同,就不会插入,因为是一个树形结构
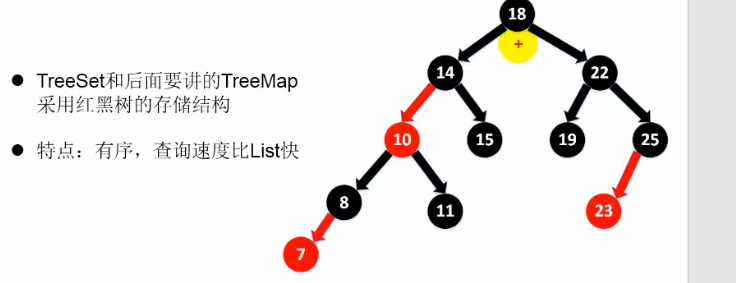
comparable 和 Comparator 的区别
- comparable 接⼝实际上是出⾃ java.lang 包 它有⼀个 compareTo(Object obj) ⽅法⽤来排序()
- comparator 接⼝实际上是出⾃ java.util 包它有⼀个 compare(Object obj1, Object obj2) ⽅法⽤来排序
当我们需要对元素进行排序的时候,我们 使用 comparator 并重写compare()方法,实现定制,Collections.sort()
当对对象时:⽐如⼀个 song 对象中的歌名和歌⼿名分别采⽤⼀种排序 ⽅法的话,我们可以重写 compareTo() ⽅法和使⽤⾃制的 Comparator ⽅法或者以两个 Comparator 来实现歌名排序和歌星名排序,第⼆种代表我们只能使⽤两个参数版的 Collections.sort()
Comparator 定制排序
1 | ArrayList<Integer> arrayList = new ArrayList<Integer>(); |
1 | 原始数组: |
重写 compareTo ⽅法实现按年龄来排序
1 | // person对象没有实现Comparable接⼝,所以必须实现,这样才不会出错,才可 |
1 | public static void main(String[] args) { |
5-⼩红
10-王五
20-李四
30-张
Map接口:
Map接口继承树
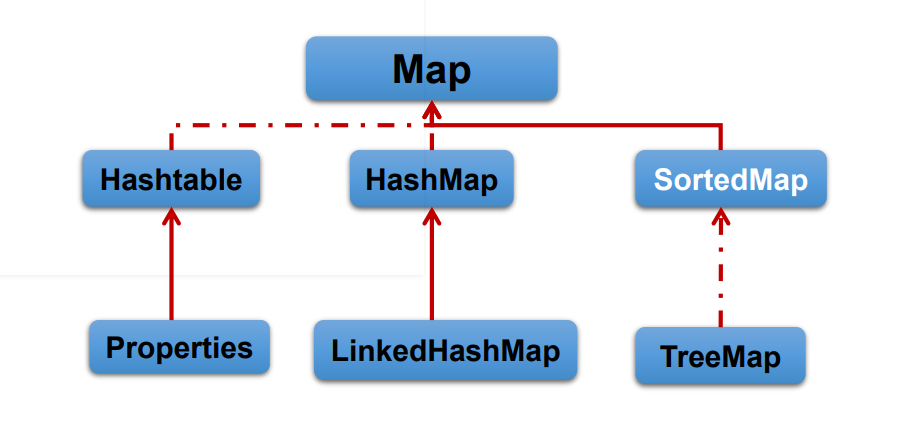
|———HashMap:
Map的主要实现类,线程不安全,效率高
|—————LinkedHashMap :保证遍历Map元素时,可以按照添加的顺序实现遍历
在原有的HashMap底层数据结构上,添加一对指针,指向前一个和后一个,对于频繁的遍历操作,执行效率高
|————TreeMap: 保证添加的Key-value 进行排序(按key进行排序),实现排序遍历,考虑Key的自然排序和定制排序,底层使用红黑树。
|————HashTable: 线程安全,效率底;不能够存储null·的key和value
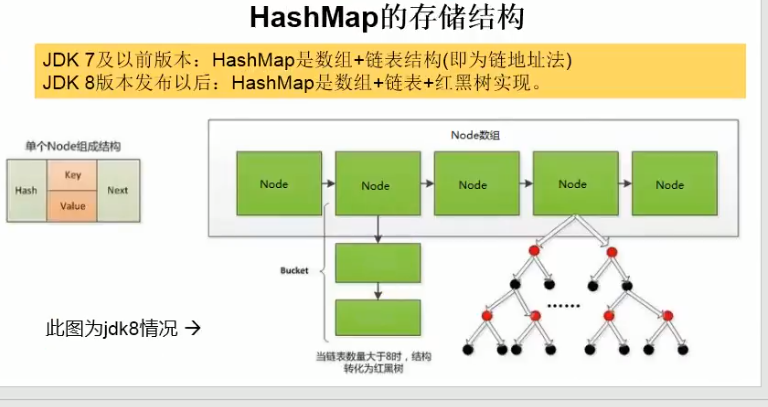
HashMap:
JDK1.8之前:
HashMap的底层是数组加链表,结合就是链表散列。HashMap通过key的hashCode经过扰动函数处理后得到hash值,通过(n-1)&hash 判断当前元素存放的位置(这里的n指的是数组的长度),如果数组
要保证低位是1,
工作原理
jdk7
调用hashcode()计算key1的hash 值,此哈希值相同经过算法计算以后,
HashMap 在map。entry静态内部类实现中存储key-value,时,HashMap使用哈希算法,当我们使用key时候,通过调用hashcode()和hash算法,先找出索引,如果不一样,添加成功,否者,找到同一个桶之后,使用quals检验值是否存在,如果存在,会覆盖value,如果不存在,会创建一个新的entry(包括属性有;key ,value,next) 属性。默认扩容为原来的两倍.

Jdk8相较于Jdk7在底层实现的方面的不同:
1、new HashMap():底层没有创建一个长度为16 的数组
2、jdk 8 底层是 Node[] 不是entry
3、首次调用put 方法时,底层创建长度为16的数组
4、jdk7底层结构数组链表,jdk8 中的底层:数组+链表+红黑树
为了避免链表过长,查询速度变为了线性, 当数组上的某一索引元素以链表的形式存在的数据个数大于>8 ,且当前的长度>64 此时索引的位置上的说有数据改为红黑树

对HashMap中put/get方法的认识?
HashMap
jdk8:
底层存储数据使用的是node:
1 | // static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } |
put方法:
1 | public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } |
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) //首次初始化数组 n = (tab = resize()).length; //找到当前数组的元素值 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } |
resize:
1 | final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; } |
LinkedHashMap的底层原理(待完成):
map常用方法:

1.1.3. 集合框架底层数据结构总结
1.1.3.1. List
Arraylist:Object[]数组 线程不安全,查询速度快。底层数据结构是数组结构 底层使用Object[ ]存储Vector:Object[]数组 线程安全,但速度慢,已被ArrayList替代LinkedList: 双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环,线程不安全。增删速度快。底层数据结构是链表结构
1.1.3.2. Set
HashSet(无序,唯一): 基于HashMap实现的,底层采用HashMap来保存元素LinkedHashSet:LinkedHashSet是HashSet的子类,并且其内部是通过LinkedHashMap来实现的。有点类似于我们之前说的LinkedHashMap其内部是基于HashMap实现一样,不过还是有一点点区别的TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树)
1.1.3.3 Queue
PriorityQueue:Object[]数组来实现二叉堆ArrayQueue:Object[]数组 + 双指针
再来看看 Map 接口下面的集合。
1.1.3.4. Map
HashMap: JDK1.8 之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间LinkedHashMap:LinkedHashMap继承自HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:《LinkedHashMap 源码详细分析(JDK1.8)》Hashtable: 数组+链表组成的,数组是Hashtable的主体,链表则是主要为了解决哈希冲突而存在的TreeMap: 红黑树(自平衡的排序二叉树)
1.1.2. 说说 List, Set, Queue, Map 四者的区别?
List(对付顺序的好帮手): 存储的元素是有序的、可重复的。Set(注重独一无二的性质): 存储的元素是无序的、不可重复的。Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。Map(用 key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),”x” 代表 key,”y” 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
1.2.1. Arraylist 和 Vector 的区别?
ArrayList是List的主要实现类,底层使用Object[ ]存储,适用于频繁的查找工作,效率高 线程不安全 ,;Vector是List的古老实现类,底层使用Object[ ]存储,使用synchronized效率低线程安全的。
1.2.2. Arraylist 与 LinkedList 区别?
- 是否保证线程安全:
ArrayList和LinkedList都是不同步的,也就是不保证线程安全; - 底层数据结构:
Arraylist底层使用的是Object数组;LinkedList底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!) - 插入和删除是否受元素位置的影响:
ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。LinkedList采用链表存储,所以,如果是在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、removeLast()),近似 O(1),如果是要在指定位置i插入和删除元素的话(add(int index, E element),remove(Object o)) 时间复杂度近似为 O(n) ,因为需要先移动到指定位置再插入。
- 是否支持快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。 - 内存空间占用: ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
1.2.2. 负载因子值的大小,对HashMap有什么影响?
负载因子的大小决定了HashMap的数据密度
负载因子越大密度越大,发生碰撞的几率越高,数组中的链表越容易长,造成查询或插入时的比较次数也越小,性能会更高,但是会浪费一定的内容空间。而且经常扩容会影响性能建议初始化预设大一点的空间
按照其他语言的参考及研究,会考虑将负载因子设置为0.7~0.75,此时平均检索长度接近于常数
1.2.3⽐较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
- HashSet 是 Set 接⼝的主要实现类 ,HashSet 的底层是 HashMap,线程不安全的,可以存储 null 值;
- LinkedHashSet 是 HashSet 的⼦类,能够按照添加的顺序遍历;
- TreeSet 底层使⽤红⿊树,能够按照添加元素的顺序进⾏遍历,排序的⽅式有⾃然排序和定制排序
Collections常用方法:
Collections 工具类常用方法:
- 排序
- 查找,替换操作
- 同步控制(不推荐,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合)
查找,替换操作
void reverse(List):
反转List中元素的顺序
void shuffle(List):
对List集合元素进行随机排序
void sort(List):
根据元素的自然顺序对指定List集合元素按升序排序
void sort(List,Comparator):
根据指定的Comparator产生的顺序对List集合元素进行排序
void swap(List,int,int):
将指定list集合中的i处元素和j处元素进行交换
查找替换操作:
1 | int binarySearch(List list, Object key)//对List进行二分查找,返回索引,注意List必须是有序的 |
同步控制:
Collections 提供了多个synchronizedXxx()方法·,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。我们知道 HashSet,TreeSet,ArrayList,LinkedList,HashMap,TreeMap 都是线程不安全的。Collections 提供了多个静态方法可以把他们包装成线程同步的集合。
- synchronizedCollection(Collection
c) //返回指定 collection 支持的同步(线程安全的) - collection.synchronizedList(List
list)//返回指定列表支持的同步(线程安全的) - List.synchronizedMap(Map<K,V> m) //返回由指定映射支持的同步(线程安全的)
- Map。synchronizedSet(Set
s) //返回指定 set 支持的同步(线程安全的)set。
枚举类和注解:
枚举
类的对象只有有限个,确定的
当需要进行定义一组常量时,强烈建议使用枚举类:
如何使用关键字enum定义枚举类;
使用关键字:
1 | //类的对象只有有限个,确定的 |
test:
1 | public void TestEnum(){ |
使用自定义:
1 | package wz.TestEnum; |
注解:
●注解(Annotation)概述·
jdk5.0 开始
Annotation其实就是代码里的特殊标记,这些标记可以在编译,类加载,运行时被读取,并执行相应的处理。通过使用Annotation,程序员可以在不改变原有逻辑的情况下,在源文件中嵌入一些补充信息。代码分析工具、开发工具和部署工具可以通过这些补充信息进行验证或者进行部署。
Annotation可以像修饰符一样被使用,可用于修饰包,类,构造器,方法,成员变量,参数,局部变量的声明,这些信息被保存在Annotation的“name=value”对中。
框架 =注解+ 反射+设计模式
●自定义AnnotationJDK中的元注解
- 自定义注解通常都会指明两个元注解:retention、target
- 利用反射获取注解信息(在反射部分涉及)
●JDK 8中注解的新特性
元数据
@retention:
指定所修饰的annotation的生命周期:source\class,只有声明为runtime 生命周期的注解,才能通过反射
@target:
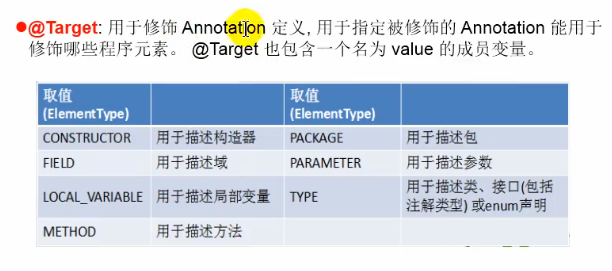
用于指定被修饰的Annotation能用于修饰哪些程序元素
1 | public enum ElementType { /** Class, interface (including annotation type), or enum declaration */ TYPE, /** Field declaration (includes enum constants) */ //属性 FIELD, /** Method declaration */ //方法 METHOD, /** Formal parameter declaration */ //私有的 PARAMETER, /** Constructor declaration */ //构造函数 CONSTRUCTOR, /** Local variable declaration */ //本地变量 LOCAL_VARIABLE, /** Annotation type declaration */ //注释类型 ANNOTATION_TYPE, /** Package declaration */ //包注解 PACKAGE, /** * Type parameter declaration * * @since 1.8 */ //类型注解,表示该注解能够写在类型变量的声明语句中(如:泛型的声明 TYPE_PARAMETER, /** * Use of a type * * @since 1.8 */ //该注解能够写在使用类型的任何语句之中 TYPE_USE} |
@Documented:
用于指定被该元Annotation修饰的Annotation类将被javadoc工具提取成文档。默认情况下,javadoc是不包括注解的。>定义为Documented的注解必须设置Retention值为RUNTIME。
@inherited
修饰的Annotation将具有继承性,如果某个类使用了被该注解修饰的Annotion,那么其子类将自动具有该注解
比如:如果把标有@Inherited注解的自定义的注解标注在类级别上,子类则可以继承父类类级别的注解
利用反射获取信息:
当一个Annotation类型被定义为运行时annotation后,该注解才是运行时可见,当class文件被载入时保存在class 文件中Annotation 才会被虚拟机读取
程序可以调用annotateElement对象来访问Annotation的信息
jdk8中的新注解:
可重复注解:
1、在MyAnnotation上面声明@Repeatable,与成员值进行绑定 MyAnnotation.class
类型注解:

注解样例:
1 | package com.jfinal.plugin.ehcache; |
泛型:
1.1为什么要有泛型(Generic):
在jdk1.5之前只能把元素类型设计为Object,把元素的类型设计成一个参数,从而达到能够对不同的对象进行重用
所谓泛型:就是允许在定义类中、接口时通过一个标识符表示某个属性的类型或者某个方法的返回值以及参数类型 。这个类型将在使用时确定(例如: 继承或者实习这个接口用这个声明变量、创建对象)确定(传入实际的参数,也称为类型的参数)

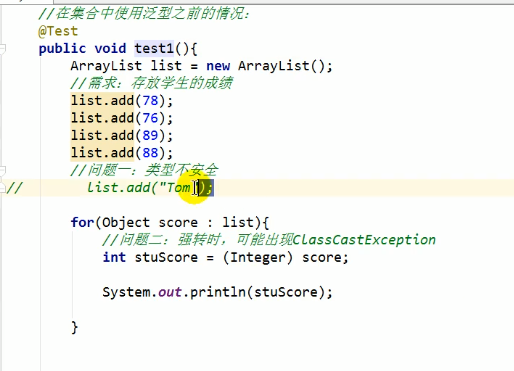
如果没有使用泛型在取出时就会有问题

使用的时候只需要指定你要的什么类型,然后在进行使用

泛型嵌套:

通配符的使用:
1、使用类型通配符:类型变量的限定 ,能够对指定的进行限制
List<? extends Object> 其父类必须是Object
对于List<?>不能够向其内部添加数据
//获取(读取):允许读取数据,读取的数据为Object 类型
通配符指定上限:
上限extends:
使用时指定的类型必须继承某个类,或者实现某个接口
通配符指定下限:
下限super:s
使用时指定的类型不能小于操作的类
(无穷小,Number) 只允许泛型为Number及Number子类的引用 只允许泛型为Number及Number父类的引用 只允许泛型为实现Comparaable接口的实现类的引用 便于提取出 泛型的数据: 首先人的信息进行封装 ,能够给指定的人显示所需要显示的信息 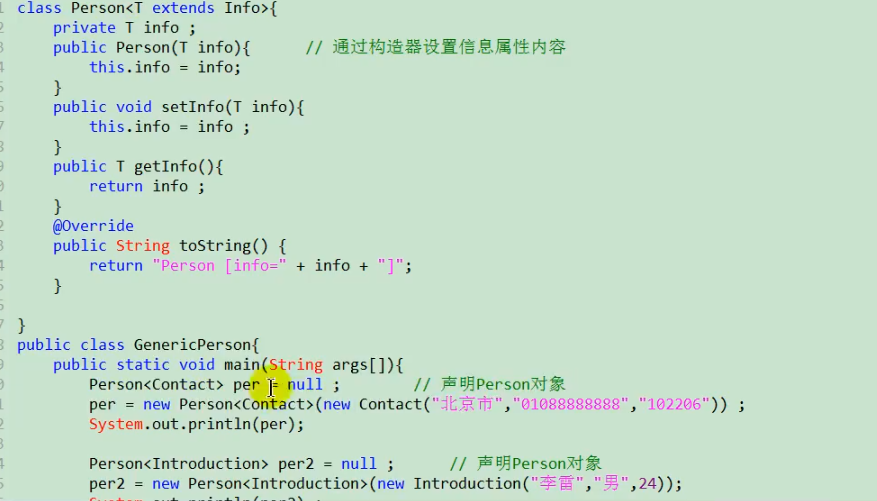  1 | /** * 这个只能传递T类型的数据 * 返回值 就是Demo<T> 实例化传递的对象类型 * @param data * @return */ private T getListFisrt(List<T> data) { |
1 | // 将对象转换为字符串 Object-->String<T> 声明泛型 返回值为string 传入值为 T型 |
1 | Slf4jLogFilter slf4jLogFilter = new Slf4jLogFilter(); |
1 | static DruidPlugin druidplugin; |
1 | public void test2() { Class cla = User.class; try {// 通过反射获取对象的构造方法 |
1 | // 获取class的实例的方式 |
1 | Class<User> personClass = User.class; /** * newInstance() 调用此方法,创建对应的运行时对象,内部调用了运行时类的空参构造 *要想此方法正常的创建运行时类的对象 * 1 运行时类必须要提供空参的构造器 * 空参的构造器的访问权限,通常设置为public * 在Javabean 中要求提供一个public的空参构造器,原因 * 1 便于通过反射,创建运行时类的对象 * 便于子类继承此运行时类时,默认调用super()时,保证父类有此构造器 * */ User obj =personClass.newInstance(); System.out.println("obj = " + obj); |
1 | package wz.Reflection.TestField;import org.junit.Test;import wz.Reflection.Person;import java.lang.annotation.Annotation;import java.lang.reflect.*;import java.time.Period;public class TestField { public void test1() { Class cl = Person.class;// 获取属性结构 //拿取public 修饰的属性值// getFields(): 获取当前运行时类及其父类中的属性,该属性必须为public 修饰权限的属性值 Field[] fields = cl.getFields(); for (Field f : fields ) { System.out.println(f); } System.out.println("------------");// getDeclaredFields():获取当前运行时类中声明的所有属性,(不能包含父类中的属,当前类中使用public 修饰的值) Field[] declareFields = cl.getDeclaredFields(); for (Field f : declareFields ) { System.out.println(f); } } // 权限修饰符 数据类型 变量名 @Test public void test() { Class clazz = Person.class; Field[] declareFields = clazz.getDeclaredFields(); for (Field f : declareFields ) {// 1.权限修饰符,获取权限修饰符 int modifiers = f.getModifiers(); System.out.print(Modifier.toString(modifiers) + "\t");// 2.获取数据类型值 Class type = f.getType(); System.out.print(type + "\t");// 3.获取数据变量名 /** * private class java.lang.String name * public int age * public int id */ String name = f.getName(); System.out.print(name); System.out.println(); } } /** * 获取运行时类的构造器 */ @Test public void Test() { Class clazz = Person.class;// getConstructors()获取当前运行时类中声明为public 的构造器 Constructor[] constructors = clazz.getConstructors(); for (Constructor c : constructors) { System.out.println(c); /** * public wz.Reflection.Person() * public wz.Reflection.Person(java.lang.String) */ }// 获取当前运行是类的所有构造器 Constructor[] constructor = clazz.getDeclaredConstructors(); for (Constructor c : constructor) { System.out.println(c); } } /** * 获取运行时类的父类及父类的泛型 */ @Test public void TestT() {// supec = class java.lang.Class Class c = Person.class; Class supec = c.getClass(); System.out.println("supec = " + supec); } /** * 获取运行时类带泛型的父类的泛型 */ @Test public void testSuperClass() {// genericSuperclass = wz.Reflection.Creature<java.lang.String> Class<Person> personClass = Person.class; Type genericSuperclass = personClass.getGenericSuperclass(); System.out.println("genericSuperclass = " + genericSuperclass); } /** * 获运行时类的带泛型的父类的泛型 * actualTypeArgument[0] = class java.lang.String */ @Test public void TestSuperClass() { Class clazz = Person.class; Type genericSupperClass = clazz.getGenericSuperclass(); ParameterizedType parameterizedType = (ParameterizedType) genericSupperClass;// 获取泛型的数据 Type[] actualTypeArgument = parameterizedType.getActualTypeArguments(); System.out.println("actualTypeArgument[0] = " + (Class) actualTypeArgument[0]); } /** * 获取运行时类的接口 */ @Test public void TestInterface() { /* interface java.lang.Comparable interface wz.Reflection.MyInterface */ Class clazz = Person.class; Class[] interfaces = clazz.getInterfaces(); for (Class c : interfaces) { System.out.println(c); }// 获取运行时类的父类的接口,先得到反射的类的对象。在使用对象进行进行后一步的操作 Class[] interfaces1 = clazz.getSuperclass().getInterfaces(); for (Class c : interfaces) { System.out.println(c); } } /** * 获取运行时类所在的包 */ @Test public void Testpackage() {// pack = package wz.Reflection Class cla = Person.class; Package pack = cla.getPackage(); System.out.println("pack = " + pack); } /** * 获取运行时类的声明的注解 */ @Test public void TestAnnotation(){ Class clazz = Person.class; Annotation[] annotations = clazz.getAnnotations(); for (Annotation a: annotations) { System.out.println("a = " + a); } }} |
1 | package wz.Reflection.TestField;import org.junit.Test;import wz.Reflection.Person;import java.lang.reflect.Constructor;import java.lang.reflect.Field;import java.lang.reflect.InvocationTargetException;import java.lang.reflect.Method;/** * 调用运行时类的中的指定的接口,属性、方法、 构造器 */public class TestReflection { public void TestField() throws NoSuchFieldException, InstantiationException, IllegalAccessException { Class clazz = Person.class;// 创建运行时类的对象 Person p = (Person) clazz.newInstance();// 获取指定的反射类型 ,指定泛型的属性,这里就是指获取反射对象的属性值 Field id = clazz.getField("id");// 属性--》动态获取的参数,指明哪个对象的属性值 + 参数2:参数值设置为多少 id.set(p,100); System.out.println("id = " + id); /** * 获取当前属性的值 */ int pid =(int) id.get(p); System.out.println("pid = " + pid); } /** * * @throws InstantiationException * @throws IllegalAccessException * @throws NoSuchFieldException */ @Test public void testField() throws InstantiationException, IllegalAccessException, NoSuchFieldException { Class clazz = Person.class;// 创建运行时类的对象 Person p = (Person) clazz.newInstance();// 获取运行时类的对象 Field name = clazz.getDeclaredField("name");// 保证当前属性值是可以访问的 name.setAccessible(true);// 获取设置指定对象的此属性值 name.set(p,"Tom"); System.out.println("name = " + name); } @Test public void testMethod() throws InstantiationException, IllegalAccessException, NoSuchMethodException, InvocationTargetException { Class clazz = Person.class;// 1 创建运行时类的对象 Person p =(Person) clazz.newInstance(); /** * 获取指定的某个方法 * 2获取某个指定的某个方法 ,指明获取的名称 参数2: 指明获取的方法的形参列表 */ Method show = clazz.getDeclaredMethod("show", String.class); /** *3 invoke(): 参数1 方法的调用者 参数2 给方法赋值的形参 * invoke() 的返回值即为对应类中调用的方法的返回值 */ Object chn = show.invoke(p, "chn"); } /** * 调用指定的构造器 */ @Test public void TestConstructor() throws NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException { Class cla = Person.class; Constructor declaredConstructor = cla.getDeclaredConstructor(String.class);// 2、b保证构造器是可以进行访问的// 3、调用此构造器创建运行时类的对象 declaredConstructor.setAccessible(true);// 3、调用此构造器创建运行时类的对象 Person tom = (Person)declaredConstructor.newInstance("tom");// 输出的是地址值 System.out.println("tom = " + tom); }} |
1 | package wz.Reflection.Proxy;import java.lang.reflect.InvocationHandler;import java.lang.reflect.Method; |
1 | public void TestCurrent(){// 代表1970年1月1日到当前时间的时间差,常用于时间戳,精确到了毫秒 long time = System.currentTimeMillis();// 时间戳 System.out.println(time);// 1630469278535 } |
1 | import java.util.Calendar; |
1 | import java.time.LocalDate; |
1 | import java.time.Instant; |
1 | //结合时区,添加当地时间偏移量 |
1 | import java.time.LocalDateTime; |
1 | LocalDate localDate = LocalDate.now(); |
1 | LocalDate localDate = LocalDate.of(2018, 1, 13); |
1 |
1 | LocalDateTime localDateTime = LocalDateTime.now(); |
1 | LocalDate localDate = LocalDate.now(); |
1 | //判断两个时间点的前后 |
1 | LocalDate now = LocalDate.now(); |
1 | //返回当前时间,根据系统时间和UTC |
1 | //计算两个日期的日期间隔-年月日 |







